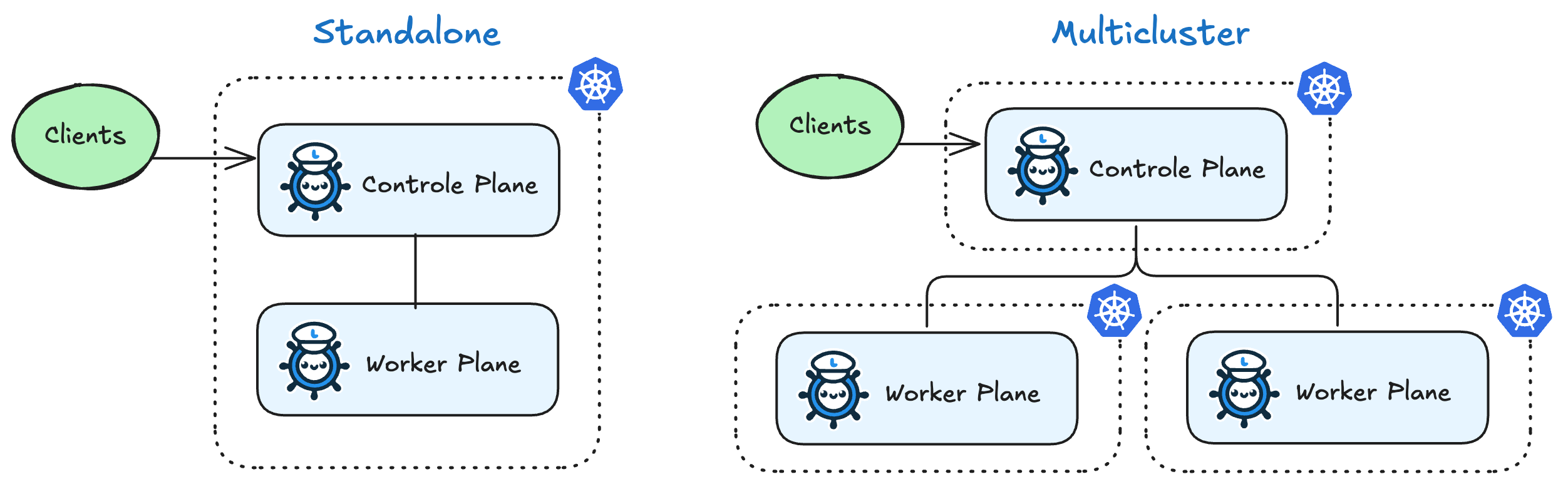
LLMariner takes ControlPlane-Worker model. The control plane gets a request and gives instructions to the worker while the worker processes a task such as inference.
Both components can operate within a single cluster, but if you want to utilize GPU resources across multiple clusters, they can also be installed into separate clusters.
LLMariner can process inference requests on CPU nodes, but it can be best used with GPU nodes. Nvidia GPU Operator is required to install the device plugin and make GPUs visible in the K8s cluster.
Preferably the ingress controller should have a DNS name or an IP that is reachable from the outside of the EKS cluster. If not, you can rely on port-forwarding to reach the API endpoints.
Note
When port-forwarding is used, the same port needs to be used consistently as the port number will be included the OIDC issuer URL. We will explain details later.
You can provision RDS and S3 in AWS, or you can deploy Postgres and MinIO inside your EKS cluster.
Install with Helm
We provide a Helm chart for installing LLMariner. You can obtain the Helm chart from our repository and install.
# Logout of helm registry to perform an unauthenticated pull against the public ECRhelm registry logout public.ecr.aws
helm upgrade --install \
--namespace <namespace> \
--create-namespace \
llmariner oci://public.ecr.aws/cloudnatix/llmariner-charts/llmariner \
--values <values.yaml>
Install CLI
Once installation completes, you can interact with the API endpoint using the OpenAI Python library, running our CLI, or directly hitting the endpoint. To download the CLI, run:
Set up the playground environment on an Amazon EC2 instance with GPUs.
You can easily set up a playground for LLMariner and learn it. In this page, we provision an EC2 instance, build a Kind cluster, and deploy LLMariner and other required components.
Warn
Playground environments are for experimentation use only. For a production-ready installation, please refere to the other installation guide.
Once all the setup completes, you can interact with the LLM service by directly hitting the API endpoints or using the OpenAI Python library.
Step 1: Install Terraform and Ansible
We use Terraform and Ansible. Follow the links to install if you haven't.
To install kubernetes.core.k8s module, run the following command:
ansible-galaxy collection install kubernetes.core
Step 2: Clone the LLMariner Repository
We use the Terraform configuration and Ansible playbook in the LLMariner repository. Run the following commands to clone the repo and move to the directory where the Terraform configuration file is stored.
git clone https://github.com/llmariner/llmariner.git
cd llmariner/provision/aws
Step 3: Run Terraform
First create a local.tfvars file for your deployment. Here is an example.
profile is an AWS profile that is used to create an EC2 instance. public_key_path and private_key_path specify an SSH key used to access the EC2 instance.
Note
See variables.tf for other customizable and default values.
Then, run the following Terraform commands to initialize and create an EC2 instance. This will approximately take 10 minutes.
If you want to run only the Ansible playbook, you can just run ansible-playbook -i inventory.ini playbook.yml.
Once the deployment completes, a Kind cluster is built in the EC2 instance and LLMariner is running in the cluster. It will take another about five minutes for LLMariner to load base models, but you can move to the next step meanwhile.
Step 4: Set up SSH Connection
You can access the API endpoint and Grafana by establishing SSH port-forwarding.
ansible all \
-i inventory.ini \
--ssh-extra-args="-L8080:localhost:80 -L8081:localhost:8081"\
-a "kubectl port-forward -n monitoring service/grafana 8081:80"
With the above command, you can hit the API via http://localhost:8080. You can directly hit the endpoint via curl or other commands, or you can use the OpenAI Python library.
You can also reach Grafana at http://localhost:8081. The login username is admin, and the password can be obtained with the following command:
ansible all \
-i inventory.ini \
-a "kubectl get secrets -n monitoring grafana -o jsonpath='{.data.admin-password}'"| tail -1 | base64 --decode;echo
Step 5: Obtain an API Key
To access LLM service, you need an API key. You can download the LLMariner CLI and use that to login the system, and obtain the API key.
# Login. Please see below for the details.llma auth login
# Create an API key.llma auth api-keys create my-key
llma auth login will ask for the endpoint URL and the issuer URL. Please use the default values for them (http://localhost:8080/v1 and http://kong-proxy.kong/v1/dex).
Then the command will open a web browser to login. Please use the following username and the password.
Username: admin@example.com
Password: password
The output of llma auth api-keys create contains the secret of the created API key. Please save the value in the environment variable to use that in the following step:
exportLLMARINER_TOKEN=<Secret obtained from llma auth api-keys create>
Step 6: Interact with the LLM Service
There are mainly three ways to interact with the LLM service.
The first option is to use the CLI. Here are example commands:
llma models list
llma chat completions create --model google-gemma-2b-it-q4_0 --role user --completion "What is k8s?"
The second option is to run the curl command and hit the API endpoint. Here is an example command for listing all available models and hitting the chat endpoint.
The third option is to use Python. Here is an example Python code for hitting the chat endpoint.
fromosimportenvironfromopenaiimportOpenAIclient=OpenAI(base_url="http://localhost:8080/v1",api_key=environ["LLMARINER_TOKEN"])completion=client.chat.completions.create(model="google-gemma-2b-it-q4_0",messages=[{"role":"user","content":"What is k8s?"}],stream=True)forresponseincompletion:print(response.choices[0].delta.content,end="")print("\n")
Please visit tutorials{.interpreted-text role=“doc”} to further exercise LLMariner.
Step 7: Clean up
Run the following command to destroy the EC2 instance.
terraform destroy -var-file=local.tfvars
3 - Set up a Playground on a CPU-only Kind Cluster
Set up the playground environment on a local kind cluster (CPU-only).
Following this guide provides you with a simplified, local LLMariner installation by using the Kind and Helm. You can use this simple LLMariner deployment to try out features without GPUs.
Warn
Playground environments are for experimentation use only. For a production-ready installation, please refere to the other installation guide.
Before you begin
Before you can get started with the LLMariner deployment you must install:
The installation files are in provision/dev/. Create a new Kubernetes cluster using kind by running:
cd provision/dev/
./create_cluster.sh single
Step 3: Install LLMariner
To install LLMariner using helmfile, run the following commands:
helmfile apply --skip-diff-on-install
Tips
You can filter the components to deploy using the --selector(-l) flag. For example, to filter out the monitoring components, set the -l tier!=monitoring flag. For deploying just the llmariner, use -l app=llmariner.
4 - Install in a Single EKS Cluster
Install LLMariner in an EKS cluster with the standalone mode.
This page goes through the concrete steps to create an EKS cluster, create necessary resources, and install LLMariner. You can skip some of the steps if you have already made necessary installation/setup.
Step 1. Provision an EKS cluster
Step 1.1. Create a new cluster with Karpenter
Either follow the Karpenter getting started guide and create an EKS cluster with Karpenter, or run the following simplified installation steps.
Once Karpenter is installed, we need to create an EC2NodeClass and a NodePool so that GPU nodes are provisioned. We configure blockDeviceMappings in the EC2NodeClass definition so that nodes have sufficient local storage to store model files.
An ingress controller is required to route HTTP/HTTPS requests to the LLMariner components. Any ingress controller works, and you can skip this step if your EKS cluster already has an ingress controller.
Here is an example that installs Kong and make the ingress controller reachable via AWS loadbalancer:
We will create an RDS in the same VPC as the EKS cluster so that it can be reachable from the LLMariner components. Here are example commands for creating a DB subnet group:
LLMariner will create additional databases on the fly for each API service (e.g., job_manager, model_manager). You can see all created databases by running SELECT count(datname) FROM pg_database;.
Step 3. Create an S3 bucket
We will create an S3 bucket where model files are stored. Here is an example
# Please change the bucket name to something else.exportS3_BUCKET_NAME="llmariner-demo"exportS3_REGION="us-east-1"aws s3api create-bucket --bucket "${S3_BUCKET_NAME}" --region "${S3_REGION}"
If you want to set up Milvus for RAG, please create another S3 bucket for Milvus:
# Please change the bucket name to something else.exportMILVUS_S3_BUCKET_NAME="llmariner-demo-milvus"aws s3api create-bucket --bucket "${MILVUS_S3_BUCKET_NAME}" --region "${S3_REGION}"
Pods running in the EKS cluster need to be able to access the S3 bucket. We will create an IAM role for service account for that.
Then install the Helm chart. Milvus requires access to the S3 bucket. To use the same service account created above, we deploy Milvus in the same namespace as LLMariner.
Run the following command to set up a values.yaml and install LLMariner with Helm.
# Set the endpoint URL of LLMariner. Please change if you are using a different ingress controller.exportINGRESS_CONTROLLER_URL=http://$(kubectl get services -n kong kong-proxy-kong-proxy -o jsonpath='{.status.loadBalancer.ingress[0].hostname}')exportPOSTGRES_SECRET_NAME="db-secret"cat << EOF | envsubst > llmariner-values.yaml
global:
# This is an ingress configuration with Kong. Please change if you are using a different ingress controller.
ingress:
ingressClassName: kong
# The URL of the ingress controller. this can be a port-forwarding URL (e.g., http://localhost:8080) if there is
# no URL that is reachable from the outside of the EKS cluster.
controllerUrl: "${INGRESS_CONTROLLER_URL}"
annotations:
# To remove the buffering from the streaming output of chat completion.
konghq.com/response-buffering: "false"
database:
host: "${POSTGRES_ADDR}"
port: ${POSTGRES_PORT}
username: "${POSTGRES_USER}"
ssl:
mode: require
createDatabase: true
databaseSecret:
name: "${POSTGRES_SECRET_NAME}"
key: password
objectStore:
s3:
bucket: "${S3_BUCKET_NAME}"
region: "${S3_REGION}"
endpointUrl: ""
prepare:
database:
createSecret: true
secret:
password: "${POSTGRES_PASSWORD}"
dex-server:
staticPasswords:
- email: admin@example.com
# bcrypt hash of the string: $(echo password | htpasswd -BinC 10 admin | cut -d: -f2)
hash: "\$2a\$10\$2b2cU8CPhOTaGrs1HRQuAueS7JTT5ZHsHSzYiFPm1leZck7Mc8T4W"
username: admin-user
userID: admin-id
file-manager-server:
serviceAccount:
create: false
name: "${LLMARINER_SERVICE_ACCOUNT_NAME}"
inference-manager-engine:
serviceAccount:
create: false
name: "${LLMARINER_SERVICE_ACCOUNT_NAME}"
model:
default:
runtimeName: vllm
preloaded: true
resources:
limits:
nvidia.com/gpu: 1
overrides:
meta-llama/Meta-Llama-3.1-8B-Instruct-q4_0:
contextLength: 16384
google/gemma-2b-it-q4_0:
runtimeName: ollama
resources:
limits:
nvidia.com/gpu: 0
sentence-transformers/all-MiniLM-L6-v2-f16:
runtimeName: ollama
resources:
limits:
nvidia.com/gpu: 0
inference-manager-server:
service:
annotations:
# These annotations are only meaningful for Kong ingress controller to extend the timeout.
konghq.com/connect-timeout: "360000"
konghq.com/read-timeout: "360000"
konghq.com/write-timeout: "360000"
job-manager-dispatcher:
serviceAccount:
create: false
name: "${LLMARINER_SERVICE_ACCOUNT_NAME}"
notebook:
# Used to set the base URL of the API endpoint. This can be same as global.ingress.controllerUrl
# if the URL is reachable from the inside cluster. Otherwise you can change this to the
# to the URL of the ingress controller that is reachable inside the K8s cluster.
llmarinerBaseUrl: "${INGRESS_CONTROLLER_URL}/v1"
model-manager-loader:
serviceAccount:
create: false
name: "${LLMARINER_SERVICE_ACCOUNT_NAME}"
baseModels:
- meta-llama/Meta-Llama-3.1-8B-Instruct-q4_0
- google/gemma-2b-it-q4_0
- sentence-transformers/all-MiniLM-L6-v2-f16
# Required when RAG is used.
vector-store-manager-server:
serviceAccount:
create: false
name: "${LLMARINER_SERVICE_ACCOUNT_NAME}"
vectorDatabase:
host: "${MILVUS_ADDR}"
llmEngineAddr: ollama-sentence-transformers-all-minilm-l6-v2-f16:11434
EOFhelm upgrade --install \
--namespace llmariner \
--create-namespace \
llmariner oci://public.ecr.aws/cloudnatix/llmariner-charts/llmariner \
-f llmariner-values.yaml
Note
Starting from Helm v3.8.0, the OCI registry is supported by default. If you are using an older version, please upgrade to v3.8.0 or later. For more details, please refer to Helm OCI-based registries.
Note
If you are getting a 403 forbidden error, please try docker logout public.ecr.aws. Please see AWS document for more details.
If you would like to install only the control-plane components or the worker-plane components, please see multi_cluster_deployment{.interpreted-text role=“doc”}.
Step 6. Verify the installation
You can verify the installation by sending sample chat completion requests.
Note, if you have used LLMariner in other cases before you may need to delete the previous config by running rm -rf ~/.config/llmariner
The default login user name is admin@example.com and the password is
password. You can change this by updating the Dex configuration
(link).
echo"This is your endpoint URL: ${INGRESS_CONTROLLER_URL}/v1"llma auth login
# Type the above endpoint URL.llma models list
llma chat completions create --model google-gemma-2b-it-q4_0 --role user --completion "what is k8s?"llma chat completions create --model meta-llama-Meta-Llama-3.1-8B-Instruct-q4_0 --role user --completion "hello"
Optional: Monitor GPU utilization
If you would like to install Prometheus and Grafana to see GPU utilization, run:
First follow the cert-manager installation document and install cert-manager to your K8s cluster if you don’t have one. Then create a ClusterIssuer for your domain. Here is an example manifest that uses Let's Encrypt.
Install LLMariner in an on-premise Kubernetes cluster with the standalone mode.
This page goes through the concrete steps to install LLMariner on a on-premise K8s cluster (or a local K8s cluster).
You can skip some of the steps if you have already made necessary installation/setup.
Note
Installation of Postgres, MinIO, SeaweedFS, and Milvus are just example purposes, and
they are not intended for the production usage.
Please configure based on your requirements if you want to use LLMariner for your production environment.
Step 1. Install Nvidia GPU Operator
Nvidia GPU Operator is required to install the device plugin and make GPU resources visible in the K8s cluster. Run:
An ingress controller is required to route HTTP/HTTPS requests to the LLMariner components. Any ingress controller works, and you can skip this step if your EKS cluster already has an ingress controller.
Here is an example that installs Kong and make the ingress controller:
LLMariner requires an S3-compatible object store such as MinIO or SeaweedFS.
First set environmental variables to specify installation configuration:
# Bucket name and the dummy region.exportS3_BUCKET_NAME=llmariner
exportS3_REGION=dummy
# Credentials for accessing the S3 bucket.exportAWS_ACCESS_KEY_ID=llmariner-key
exportAWS_SECRET_ACCESS_KEY=llmariner-secret
Then install an object store. Here are the example installation commands for MinIO and SeaweedFS.
helm upgrade --install --wait \
--namespace minio \
--create-namespace \
minio oci://registry-1.docker.io/bitnamicharts/minio \
--set auth.rootUser=minioadmin \
--set auth.rootPassword=minioadmin \
--set defaultBuckets="${S3_BUCKET_NAME}"kubectl port-forward -n minio service/minio 9001&# Wait until the port-forwarding connection is established.sleep 5# Obtain the cookie and store in cookies.txt.curl \
http://localhost:9001/api/v1/login \
--cookie-jar cookies.txt \
--request POST \
--header 'Content-Type: application/json'\
--data @- << EOF
{
"accessKey": "minioadmin",
"secretKey": "minioadmin"
}
EOF# Create a new API key.curl \
http://localhost:9001/api/v1/service-account-credentials \
--cookie cookies.txt \
--request POST \
--header "Content-Type: application/json"\
--data @- << EOF >/dev/null
{
"name": "LLMariner",
"accessKey": "$AWS_ACCESS_KEY_ID",
"secretKey": "$AWS_SECRET_ACCESS_KEY",
"description": "",
"comment": "",
"policy": "",
"expiry": null
}
EOFrm cookies.txt
kill %1
Then set environmental variable S3_ENDPOINT_URL to the URL of the object store. The URL should be accessible from LLMariner pods that will run on the same cluster.
Set the environmental variables so that LLMariner can later access the Postgres database.
exportMILVUS_ADDR=milvus.milvus
Step 6. Install LLMariner
Run the following command to set up a values.yaml and install LLMariner with Helm.
# Set the endpoint URL of LLMariner. Please change if you are using a different ingress controller.exportINGRESS_CONTROLLER_URL=http://localhost:8080
cat << EOF | envsubst > llmariner-values.yaml
global:
# This is an ingress configuration with Kong. Please change if you are using a different ingress controller.
ingress:
ingressClassName: kong
# The URL of the ingress controller. this can be a port-forwarding URL (e.g., http://localhost:8080) if there is
# no URL that is reachable from the outside of the EKS cluster.
controllerUrl: "${INGRESS_CONTROLLER_URL}"
annotations:
# To remove the buffering from the streaming output of chat completion.
konghq.com/response-buffering: "false"
database:
host: "${POSTGRES_ADDR}"
port: ${POSTGRES_PORT}
username: "${POSTGRES_USER}"
ssl:
mode: disable
createDatabase: true
databaseSecret:
name: postgres
key: password
objectStore:
s3:
endpointUrl: "${S3_ENDPOINT_URL}"
bucket: "${S3_BUCKET_NAME}"
region: "${S3_REGION}"
awsSecret:
name: aws
accessKeyIdKey: accessKeyId
secretAccessKeyKey: secretAccessKey
prepare:
database:
createSecret: true
secret:
password: "${POSTGRES_PASSWORD}"
objectStore:
createSecret: true
secret:
accessKeyId: "${AWS_ACCESS_KEY_ID}"
secretAccessKey: "${AWS_SECRET_ACCESS_KEY}"
dex-server:
staticPasswords:
- email: admin@example.com
# bcrypt hash of the string: $(echo password | htpasswd -BinC 10 admin | cut -d: -f2)
hash: "\$2a\$10\$2b2cU8CPhOTaGrs1HRQuAueS7JTT5ZHsHSzYiFPm1leZck7Mc8T4W"
username: admin-user
userID: admin-id
inference-manager-engine:
model:
default:
runtimeName: vllm
preloaded: true
resources:
limits:
nvidia.com/gpu: 1
overrides:
meta-llama/Meta-Llama-3.1-8B-Instruct-q4_0:
contextLength: 16384
google/gemma-2b-it-q4_0:
runtimeName: ollama
resources:
limits:
nvidia.com/gpu: 0
sentence-transformers/all-MiniLM-L6-v2-f16:
runtimeName: ollama
resources:
limits:
nvidia.com/gpu: 0
inference-manager-server:
service:
annotations:
# These annotations are only meaningful for Kong ingress controller to extend the timeout.
konghq.com/connect-timeout: "360000"
konghq.com/read-timeout: "360000"
konghq.com/write-timeout: "360000"
job-manager-dispatcher:
serviceAccount:
create: false
name: "${LLMARINER_SERVICE_ACCOUNT_NAME}"
notebook:
# Used to set the base URL of the API endpoint. This can be same as global.ingress.controllerUrl
# if the URL is reachable from the inside cluster. Otherwise you can change this to the
# to the URL of the ingress controller that is reachable inside the K8s cluster.
llmarinerBaseUrl: "${INGRESS_CONTROLLER_URL}/v1"
model-manager-loader:
baseModels:
- meta-llama/Meta-Llama-3.1-8B-Instruct-q4_0
- google/gemma-2b-it-q4_0
- sentence-transformers/all-MiniLM-L6-v2-f16
# Required when RAG is used.
vector-store-manager-server:
vectorDatabase:
host: "${MILVUS_ADDR}"
llmEngineAddr: ollama-sentence-transformers-all-minilm-l6-v2-f16:11434
EOFhelm upgrade --install \
--namespace llmariner \
--create-namespace \
llmariner oci://public.ecr.aws/cloudnatix/llmariner-charts/llmariner \
-f llmariner-values.yaml
Note
Starting from Helm v3.8.0, the OCI registry is supported by default. If you are using an older version, please upgrade to v3.8.0 or later. For more details, please refer to Helm OCI-based registries.
Note
If you are getting a 403 forbidden error, please try docker logout public.ecr.aws. Please see AWS document for more details.
If you would like to install only the control-plane components or the worker-plane components, please see multi_cluster_deployment{.interpreted-text role=“doc”}.
Step 7. Verify the installation
You can verify the installation by sending sample chat completion requests.
Note, if you have used LLMariner in other cases before you may need to delete the previous config by running rm -rf ~/.config/llmariner
The default login user name is admin@example.com and the password is
password. You can change this by updating the Dex configuration
(link).
echo"This is your endpoint URL: ${INGRESS_CONTROLLER_URL}/v1"llma auth login
# Type the above endpoint URL.llma models list
llma chat completions create --model google-gemma-2b-it-q4_0 --role user --completion "what is k8s?"llma chat completions create --model meta-llama-Meta-Llama-3.1-8B-Instruct-q4_0 --role user --completion "hello"
Optional: Monitor GPU utilization
If you would like to install Prometheus and Grafana to see GPU utilization, run:
First follow the cert-manager installation document and install cert-manager to your K8s cluster if you don’t have one. Then create a ClusterIssuer for your domain. Here is an example manifest that uses Let's Encrypt.
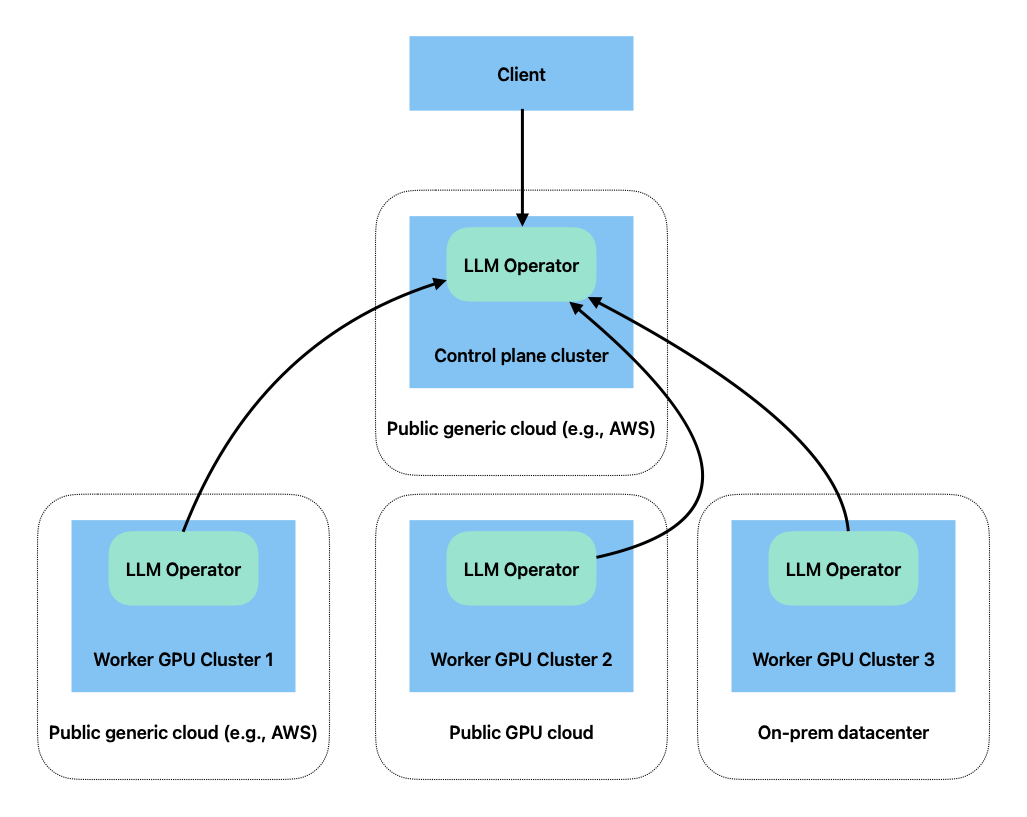
Install LLMarinr across multiple Kubernetes clusters.
LLMariner deploys Kubernetes deployments to provision the LLM stack. In a typical configuration, all the services are deployed into a single Kubernetes cluster, but you can also deploy these services on multiple Kubernetes clusters. For example, you can deploy a control plane component in a CPU K8s cluster and deploy the rest of the components in GPU compute clusters.
LLMariner can be deployed into multiple GPU clusters, and the clusters can span across multiple cloud providers (including GPU specific clouds like CoreWeave) and on-prem.
Deploying Control Plane Components
You can deploy only Control Plane components by specifying additional parameters the LLMariner helm chart.
In the values.yaml, you need to set tag.worker to false, global.workerServiceIngress.create to true, and set other values so that an ingress and a service are created to receive requests from worker nodes.
Here is an example values.yaml.
tags:worker:falseglobal:ingress:ingressClassName:kongcontrollerUrl:https://api.mydomain.comannotations:cert-manager.io/cluster-issuer:letsencryptkonghq.com/response-buffering:"false"# Enable TLS for the ingresses.tls:hosts:- api.llm.mydomain.comsecretName:api-tls# Create ingress for gRPC requests coming from worker clusters.workerServiceIngress:create:trueannotations:cert-manager.io/cluster-issuer:letsencryptkonghq.com/protocols:grpc,grpcsworkerServiceGrpcService:annotations:konghq.com/protocol:grpc# Create a separate load balancer for gRPC streaming requests from inference-manager-engine.inference-manager-server:workerServiceTls:enable:truesecretName:inference-certworkerServiceGrpcService:type:LoadBalancerport:443annotations:external-dns.alpha.kubernetes.io/hostname:inference.llm.mydomain.com# Create a separate load balancer for HTTPS requests from session-manager-agent.session-manager-server:workerServiceTls:enable:truesecretName:session-certworkerServiceHttpService:type:LoadBalancerport:443externalTrafficPolicy:Localannotations:service.beta.kubernetes.io/aws-load-balancer-type:"nlb"external-dns.alpha.kubernetes.io/hostname:session.llm.mydomain.com
Deploying Worker Components
To deploy LLMariner to a worker GPU cluster, you first need to obtain a registration key for the cluster.
llma admin clusters register <cluster-name>
The following is an example command that sets the registration key to the environment variable.
The secret needs to be created in a namespace where LLMariner will be deployed.
When installing the Helm chart for the worker components, you need to specify addition configurations in values.yaml. Here is an example.
tags:control-plane:falseglobal:objectStore:s3:endpointUrl:<S3 endpoint>region:<S3 regiona>bucket:<S3 bucket name>awsSecret:name:awsaccessKeyIdKey:accessKeyIdsecretAccessKeyKey:secretAccessKeyworker:controlPlaneAddr:api.llm.mydomain.com:443tls:enable:trueregistrationKeySecret:name:cluster-registration-keykey:regKeyinference-manager-engine:inferenceManagerServerWorkerServiceAddr:inference.llm.mydomain.com:443job-manager-dispatcher:notebook:llmarinerBaseUrl:https://api.llm.mydomain.com/v1session-manager-agent:sessionManagerServerWorkerServiceAddr:session.llm.mydomain.com:443model-manager-loader:baseModels:- <model name, e.g. google/gemma-2b-it-q4_0>
7 - Hosted Control Plane
Install just the worker plane and use it with the hosted control plane.
CloudNatix provides a hosted control plane of LLMariner.
Note
Work-in-progress. This is not fully ready yet, and the terms and conditions are subject to change as we might limit the usage based on the number of API calls or the number of GPU nodes.
CloudNatix provides a hosted control plane of LLMariner. End users can use the full functionality of LLMariner just by registering their worker GPU clusters to this hosted control plane.
Step 1. Create a CloudNatix account
Create a CloudNatix account if you haven't. Please visit https://app.cloudnatix.com. You can click one of the "Sign in or sign up" buttons for SSO login or you can click "Sign up" at the bottom for the email & password login.
Step 2. Deploy the worker plane components
Deploy the worker plane components of LLMariner into your GPU cluster.
# Logout of helm registry to perform an unauthenticated pull against the public ECRhelm registry logout public.ecr.aws
helm upgrade --install \
--namespace llmariner \
--create-namespace \
llmariner oci://public.ecr.aws/cloudnatix/llmariner-charts/llmariner \
--values <values.yaml>
Here is an example values.yaml:
tags:control-plane:falseglobal:worker:controlPlaneAddr:api.llm.cloudnatix.com:443tls:enable:trueregistrationKeySecret:name:cluster-registration-keykey:regKey# Update this to your S3 object store.objectStore:s3:bucket:cloudnatix-installation-demoendpointUrl:""region:us-west-2# Update this to the k8s secret required to access the S3 object store.awsSecret:# Name of the secret.name:aws# Secret key for the access key ID.accessKeyIdKey:accessKeyId# Secret key for the secret access key.secretAccessKeyKey:secretAccessKeyinference-manager-engine:inferenceManagerServerWorkerServiceAddr:inference.llm.cloudnatix.com:443replicaCount:2runtime:runtimeImages:ollama:mirror.gcr.io/ollama/ollama:0.6.3-rc0vllm:mirror.gcr.io/vllm/vllm-openai:v0.8.5triton:nvcr.io/nvidia/tritonserver:24.09-trtllm-python-py3engineHeartbeat:reconnectOnNoHeartbeat:trueheartbeatTimeout:120smodel:default:runtimeName:vllmoverrides:meta-llama/Llama-3.2-1B-Instruct:preloaded:falseruntimeName:vllmresources:limits:nvidia.com/gpu:1model-manager-loader:baseModels:- meta-llama/Llama-3.2-1B-Instructdownloader:kind:huggingFacehuggingFace:cacheDir:/tmp/.cache/huggingface/hubhuggingFaceSecret:name:huggingface-keyapiKeyKey:apiKeyjob-manager-dispatcher:notebook:llmarinerBaseUrl:https://api.llm.cloudnatix.com/v1session-manager-agent:sessionManagerServerWorkerServiceAddr:session.llm.cloudnatix.com:443