This is the multi-page printable view of this section. Click here to print.
Development
- 1: Technical Details
- 2: Roadmap
1 - Technical Details
Components
LLMariner provisions the LLM stack consisting of the following micro services:
- Inference Manager
- Job Manager
- Model Manager
- File Manager
- Vector Store Server
- User Manager
- Cluster Manager
- Session Manager
- RBAC Manager
- API Usage
Each manager is responsible for the specific feature of LLM services as their names indicate. The following diagram shows the high-level architecture:
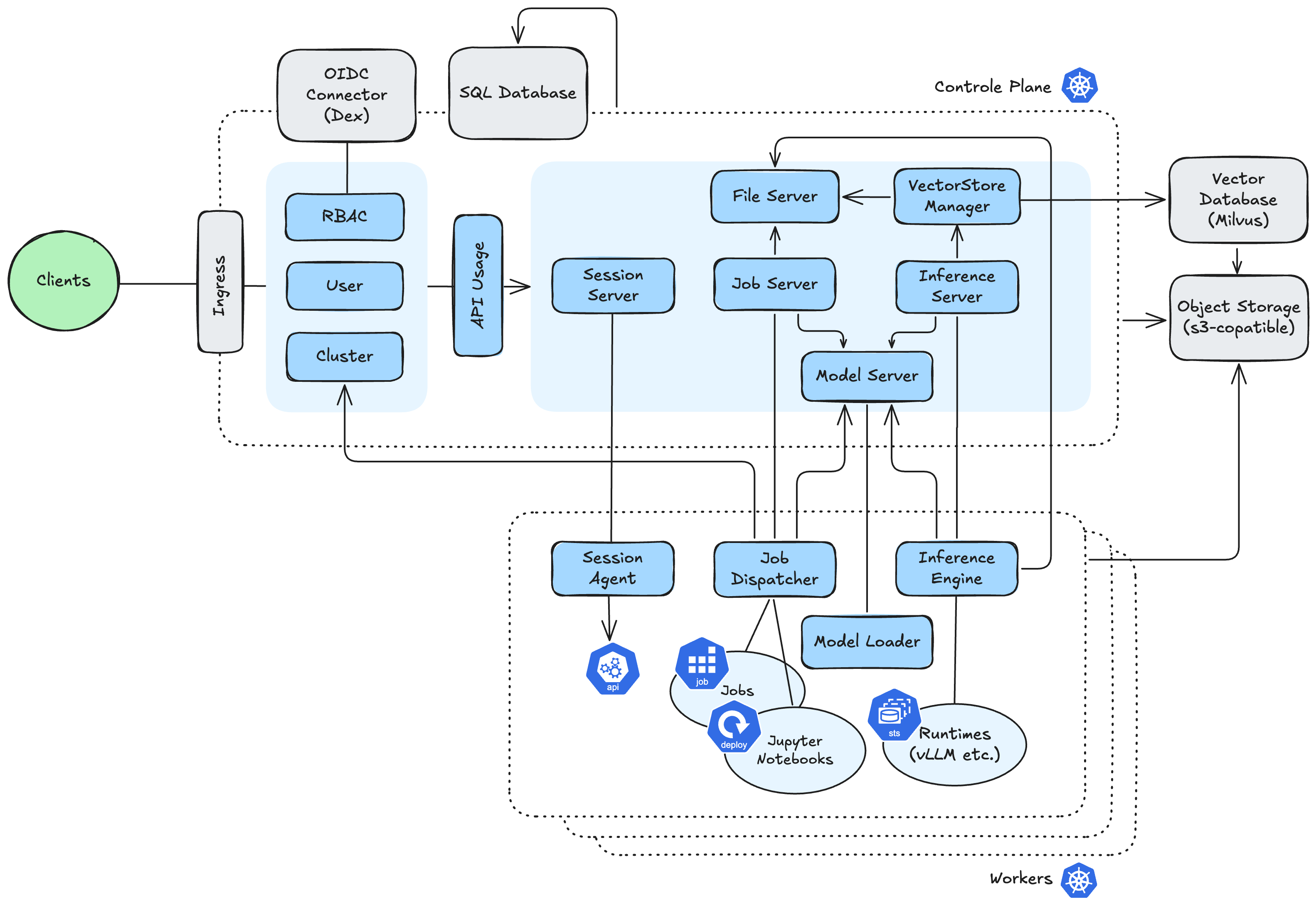
LLMariner has dependency to the following components:
Ingress controller is required to route traffic to each service. SQL database and S3-compatible object store are used to persist metadata (e.g., fine-tuning jobs), fine-tuned models, and training/validation files. Dex is used to provide authentication.
Key Technologies
Autoscaling and Dynamic Model Loading in Inference
Inference Manager dynamically loads models up on requests it receives. It also dynamically auto-scales pods based on demand.
Session Manager: Secure Access to Kubernetes API Server
LLMariner internally accesses Kubernetes API server to allow end users to access logs of fine-tuning jobs, exec into a Jupyter Notebook, etc. As end users might not have direct access to a Kubernetes API server, LLMariner uses Session Manager to provide a secure tunnel between end users and Kubernetes API server.
Session Manager consists of two components: server and agent. The agent establishes HTTP(S) connections to the server and keeps the connections. Upon receiving a request from end users, the server forwards the request to the agent using one of the established connections. Then the agent forwards the request to the Kubernetes API server.
This architecture enables the deployment where the server and the agent can run in separate Kubernetes clusters. As the agent initiates a connection (not the server), there is no need to open incoming traffic at the cluster where the agent runs. An ingress controller is still the only place where incoming traffic is sent.
Quota Management for Fine-tuning Jobs
LLMariner allows users to manage GPU quotas with integration with Kueue.
2 - Roadmap
Milestone 0 (Completed)
- OpenAI compatible API
- Models:
google-gemma-2b-it
Milestone 1 (Completed)
- API authorization with Dex
- API key management
- Quota management for fine-tuning jobs
- Inference autoscaling with GPU utilization
- Models:
Mistral-7B-Instruct,Meta-Llama-3-8B-Instruct, andgoogle-gemma-7b-it
Milestone 2 (Completed)
- Jupyter Notebook workspace creation
- Dynamic model loading & offloading in inference (initial version)
- Organization & project management
- MLflow integration
- Weights & Biases integration for fine-tuning jobs
- VectorDB installation and RAG
- Multi k8s cluster deployment (initial version)
Milestone 3 (Completed)
- Object store other than MinIO
- Multi-GPU general-purpose training jobs
- Inference optimization (e.g., vLLM)
- Models:
Meta-Llama-3-8B-Instruct,Meta-Llama-3-70B-Instruct,deepseek-coder-6.7b-base
Milestone 4 (Completed)
- Embedding API
- API usage visibility
- Fine-tuning support with vLLM
- API key encryption
- Nvidia Triton Inference Server (experimental)
- Release flow
Milestone 5 (In-progress)
- Frontend
- GPU showback
- Non-Nvidia GPU support
- Multi k8s cluster deployment (file and vector store management)
- High availability
- Monitoring & alerting
- More models
Milestone 6
- Multi-GPU LLM fine-tuning jobs
- Events and metrics for fine-tuning jobs