Do you want an API compatible with OpenAI to leverage the extensive GenAI ecosystem? If so, LLMariner is what you need. It instantly builds a software stack that provides an OpenAI-compatible API for inference, fine-tuning, and model management. Please see the presentation below to learn more:
This is the multi-page printable view of this section. Click here to print.
Welcome to LLMariner Documentation!
Transform your GPU clusters into a powerhouse for generative AI workloads
- 1: Overview
- 1.1: Why LLMariner?
- 1.2: High-Level Architecture
- 2: Getting Started
- 2.1: Installation
- 2.1.1: Install with Helm
- 2.1.2: Set up a Playground on a GPU EC2 Instance
- 2.1.3: Set up a Playground on a CPU-only Kind Cluster
- 2.1.4: Install in a Single EKS Cluster
- 2.1.5: Install in a Single On-premise Cluster
- 2.1.6: Install across Multiple Clusters
- 2.1.7: Hosted Control Plane
- 2.2: Tutorials
- 3: Features
- 3.1: Inference with Open Models
- 3.2: Model Loading
- 3.3: Retrieval-Augmented Generation (RAG)
- 3.4: Model Fine-tuning
- 3.5: General-purpose Training
- 3.6: Jupyter Notebook
- 3.7: API and GPU Usage Optimization
- 3.8: GPU Federation
- 3.9: User Management
- 3.10: Access Control with Organizations and Projects
- 4: Integration
- 4.1: Open WebUI
- 4.2: Continue
- 4.3: Aider
- 4.4: AI Shell
- 4.5: k8sgpt
- 4.6: Dify
- 4.7: n8n
- 4.8: Slackbot
- 4.9: MLflow
- 4.10: Langfuse
- 4.11: Weights & Biases (W&B)
- 5: Development
- 5.1: Technical Details
- 5.2: Roadmap
1 - Overview
A high-level introduction to LLMariner.
1.1 - Why LLMariner?
Why you need LLMariner and what it can do for you?
LLMariner (= LLM + Mariner) is an extensible open source platform to simplify the management of generative AI workloads. Built on Kubernetes, it enables you to efficiently handle both training and inference data within your own clusters. With OpenAI-compatible APIs, LLMariner leverages ecosystem of tools, facilitating seamless integration for a wide range of AI-driven applications.
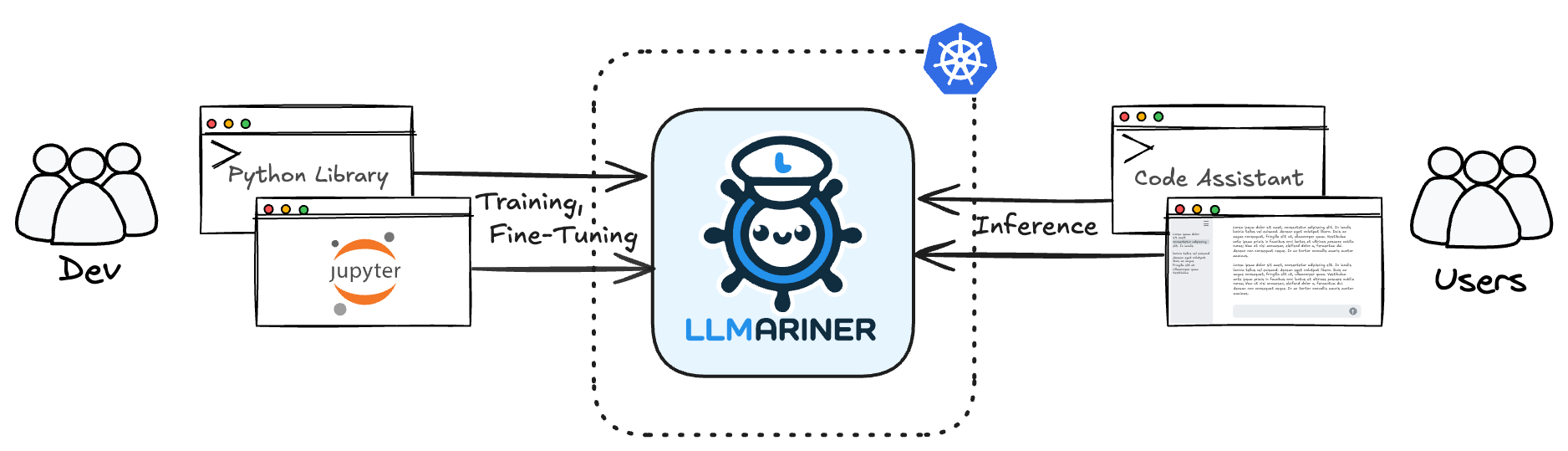
Why You Need LLMariner, and What It Can Do for You
As generative AI becomes more integral to business operations, a platform that can manage their lifecycle from data management to deployment is essential. LLMariner offers a unified solution that enables users to:
- Centralize Model Management: Manage data, resources, and AI model lifecycles all in one place, reducing the overhead of fragmented systems.
- Utilize an Existing Ecosystem: LLMariner’s OpenAI-compatible APIs make it easy to integrate with popular AI tools, such as assistant web UIs, code generation tools, and more.
- Optimize Resource Utilization: Its Kubernetes-based architecture enables efficient scaling and resource management in response to user demands.
Why Choose LLMariner
LLMariner stands out with its focus on extensibility, compatibility, and scalability:
- Open Ecosystem: By aligning with OpenAI’s API standards, LLMariner allows you to use a vast array of tools, enabling diverse use cases from conversational AI to intelligent code assistance.
- Kubernetes-Powered Scalability: Leveraging Kubernetes ensures that LLMariner remains efficient, scalable, and adaptable to changing resource demands, making it suitable for teams of any size.
- Customizable and Extensible: Built with openness in mind, LLMariner can be customized to fit specific workflows, empowering you to build upon its core for unique applications.
What’s Next
- Take a look at High-Level Architecture
- Take a look at LLMariner core Features
- Ready to Get Started?
1.2 - High-Level Architecture
An overview of the key components that make up a LLMariner.
This page provides a high-level overview of the essential components that make up a LLMariner:
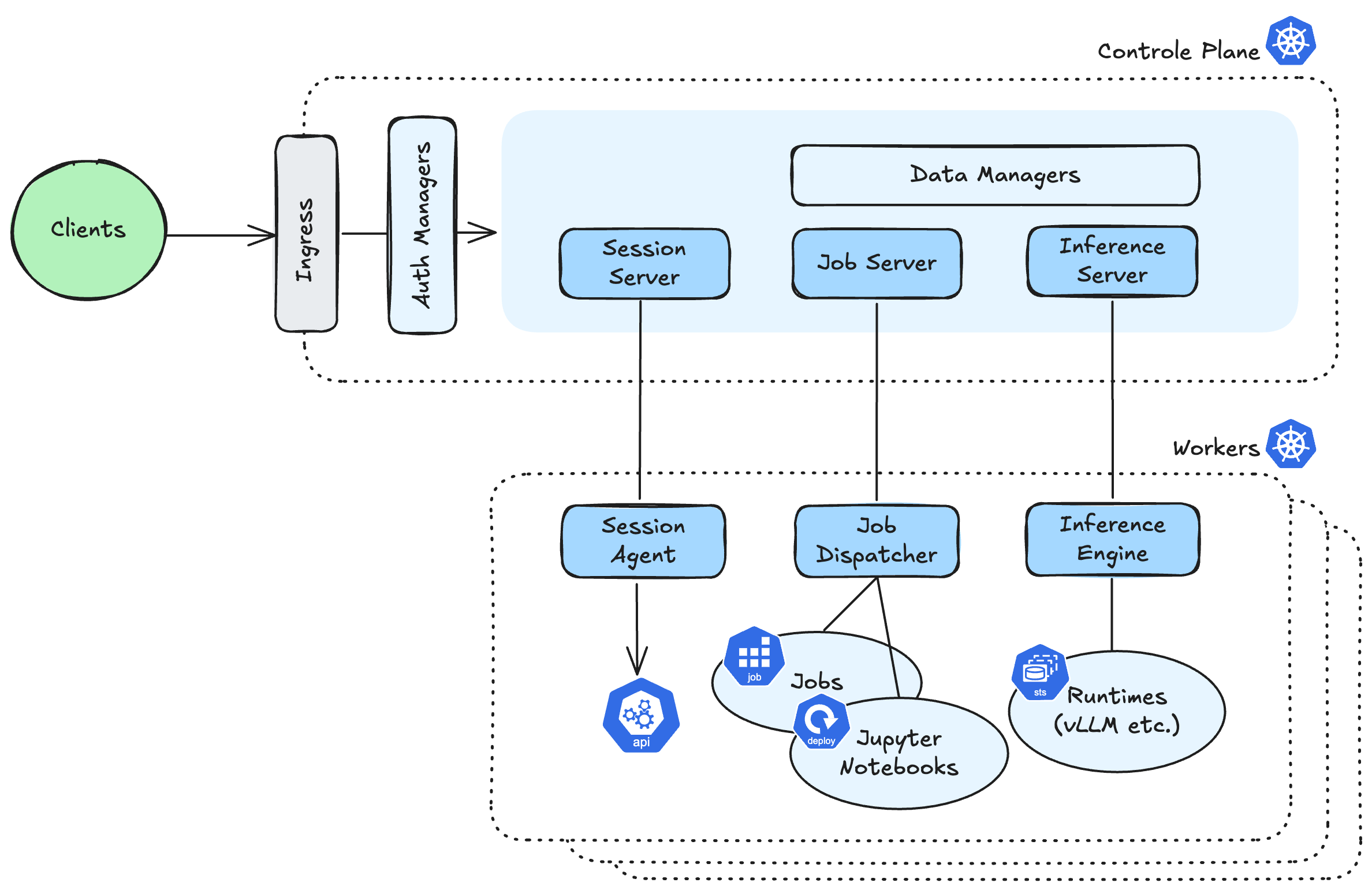
Overall Design
LLMariner consists of a control-plane and one or more worker-planes:
- Control-Plane components
- Expose the OpenAI-compatible APIs and manage the overall state of LLMariner and receive a request from the client.
- Worker-Plane components
- Run every worker cluster, process tasks using compute resources such as GPUs in response to requests from the control-plane.
Core Components
Here’s a brief overview of the main components:
- Inference Manager
- Manage inference runtimes (e.g., vLLM and Ollama) in containers, load models, and process requests. Also, auto-scale runtimes based on the number of in-flight requests.
- Job Manager
- Run fine-tuning or training jobs based on requests, and launch Jupyter Notebooks.
- Session Manager
- Forwards requests from the client to the worker cluster that need the Kubernetes API, like displaying Job logs.
- Data Managers
- Manage models, files, and vector data for RAG.
- Auth Managers
- Manage information such as users, organizations, and clusters, and perform authentication and role-based access control for API requests.
What’s Next
- Ready to Get Started?
- Take a look at the Technical Details
- Take a look at LLMariner core Features
2 - Getting Started
Get LLMariner running based on your resources and needs.
2.1 - Installation
Choose the guide that best suits your needs and platform.
LLMariner takes ControlPlane-Worker model. The control plane gets a request and gives instructions to the worker while the worker processes a task such as inference.
Both components can operate within a single cluster, but if you want to utilize GPU resources across multiple clusters, they can also be installed into separate clusters.
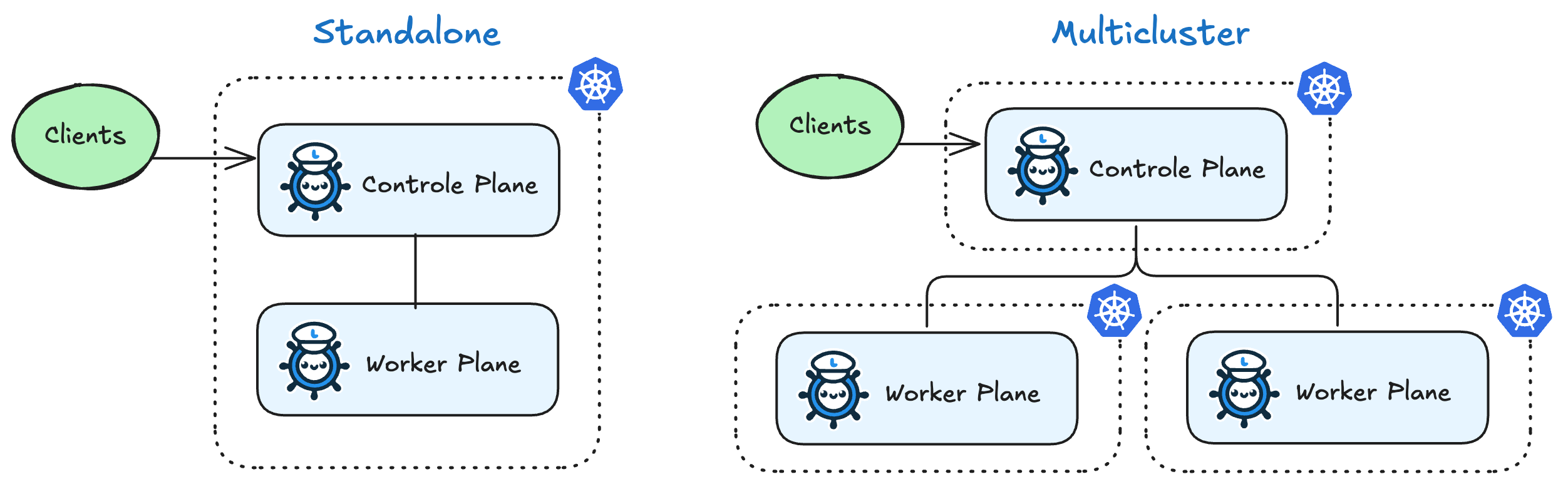
2.1.1 - Install with Helm
Install LLMariner with Helm.
Prerequisites
LLMariner requires the following resources:
- Nvidia GPU Operator
- Ingress controller (to route API requests)
- SQL database (to store jobs/models/files metadata)
- S3-compatible object store (to store training files and models)
- Milvus (for RAG, optional)
LLMariner can process inference requests on CPU nodes, but it can be best used with GPU nodes. Nvidia GPU Operator is required to install the device plugin and make GPUs visible in the K8s cluster.
Preferably the ingress controller should have a DNS name or an IP that is reachable from the outside of the EKS cluster. If not, you can rely on port-forwarding to reach the API endpoints.
Note
When port-forwarding is used, the same port needs to be used consistently as the port number will be included the OIDC issuer URL. We will explain details later.You can provision RDS and S3 in AWS, or you can deploy Postgres and MinIO inside your EKS cluster.
Install with Helm
We provide a Helm chart for installing LLMariner. You can obtain the Helm chart from our repository and install.
# Logout of helm registry to perform an unauthenticated pull against the public ECR
helm registry logout public.ecr.aws
helm upgrade --install \
--namespace <namespace> \
--create-namespace \
llmariner oci://public.ecr.aws/cloudnatix/llmariner-charts/llmariner \
--values <values.yaml>
Install CLI
Once installation completes, you can interact with the API endpoint using the OpenAI Python library, running our CLI, or directly hitting the endpoint. To download the CLI, run:
curl --silent https://llmariner.ai/get-cli | bash
mv llma <your/PATH>
brew install llmariner/tap/llma
go install github.com/llmariner/llmariner/cli/cmd@latest
Download the binary from GitHub Release Page.
2.1.2 - Set up a Playground on a GPU EC2 Instance
Set up the playground environment on an Amazon EC2 instance with GPUs.
You can easily set up a playground for LLMariner and learn it. In this page, we provision an EC2 instance, build a Kind cluster, and deploy LLMariner and other required components.
Warn
Playground environments are for experimentation use only. For a production-ready installation, please refere to the other installation guide.Once all the setup completes, you can interact with the LLM service by directly hitting the API endpoints or using the OpenAI Python library.
Step 1: Install Terraform and Ansible
We use Terraform and Ansible. Follow the links to install if you haven't.
To install kubernetes.core.k8s module, run the following command:
ansible-galaxy collection install kubernetes.core
Step 2: Clone the LLMariner Repository
We use the Terraform configuration and Ansible playbook in the LLMariner repository. Run the following commands to clone the repo and move to the directory where the Terraform configuration file is stored.
git clone https://github.com/llmariner/llmariner.git
cd llmariner/provision/aws
Step 3: Run Terraform
First create a local.tfvars file for your deployment. Here is an example.
project_name = "<instance-name> (default: "llmariner-demo")"
profile = "<aws-profile>"
public_key_path = "</path/to/public_key_path>"
private_key_path = "</path/to/private_key_path>"
ssh_ip_range = "<ingress CIDR block for SSH (default: "0.0.0.0/0")>"
profile is an AWS profile that is used to create an EC2 instance. public_key_path and private_key_path specify an SSH key used to access the EC2 instance.
Note
Seevariables.tf for other customizable and default values.Then, run the following Terraform commands to initialize and create an EC2 instance. This will approximately take 10 minutes.
terraform init
terraform apply -var-file=local.tfvars
Note
If you want to run only the Ansible playbook, you can just runansible-playbook -i inventory.ini playbook.yml.Once the deployment completes, a Kind cluster is built in the EC2 instance and LLMariner is running in the cluster. It will take another about five minutes for LLMariner to load base models, but you can move to the next step meanwhile.
Step 4: Set up SSH Connection
You can access the API endpoint and Grafana by establishing SSH port-forwarding.
ansible all \
-i inventory.ini \
--ssh-extra-args="-L8080:localhost:80 -L8081:localhost:8081" \
-a "kubectl port-forward -n monitoring service/grafana 8081:80"
With the above command, you can hit the API via http://localhost:8080. You can directly hit the endpoint via curl or other commands, or you can use the OpenAI Python library.
You can also reach Grafana at http://localhost:8081. The login username is admin, and the password can be obtained with the following command:
ansible all \
-i inventory.ini \
-a "kubectl get secrets -n monitoring grafana -o jsonpath='{.data.admin-password}'" | tail -1 | base64 --decode; echo
Step 5: Obtain an API Key
To access LLM service, you need an API key. You can download the LLMariner CLI and use that to login the system, and obtain the API key.
curl --silent https://llmariner.ai/get-cli | bash
mv llma <your/PATH>
brew install llmariner/tap/llma
go install github.com/llmariner/llmariner/cli/cmd@latest
Download the binary from GitHub Release Page.
# Login. Please see below for the details.
llma auth login
# Create an API key.
llma auth api-keys create my-key
llma auth login will ask for the endpoint URL and the issuer URL. Please use the default values for them (http://localhost:8080/v1 and http://kong-proxy.kong/v1/dex).
Then the command will open a web browser to login. Please use the following username and the password.
- Username:
admin@example.com - Password:
password
The output of llma auth api-keys create contains the secret of the created API key. Please save the value in the environment variable to use that in the following step:
export LLMARINER_TOKEN=<Secret obtained from llma auth api-keys create>
Step 6: Interact with the LLM Service
There are mainly three ways to interact with the LLM service.
The first option is to use the CLI. Here are example commands:
llma models list
llma chat completions create --model google-gemma-2b-it-q4_0 --role user --completion "What is k8s?"
The second option is to run the curl command and hit the API endpoint. Here is an example command for listing all available models and hitting the chat endpoint.
curl \
--header "Authorization: Bearer ${LLMARINER_TOKEN}" \
--header "Content-Type: application/json" \
http://localhost:8080/v1/models | jq
curl \
--request POST \
--header "Authorization: Bearer ${LLMARINER_TOKEN}" \
--header "Content-Type: application/json" \
--data '{"model": "google-gemma-2b-it-q4_0", "messages": [{"role": "user", "content": "What is k8s?"}]}' \
http://localhost:8080/v1/chat/completions
The third option is to use Python. Here is an example Python code for hitting the chat endpoint.
from os import environ
from openai import OpenAI
client = OpenAI(
base_url="http://localhost:8080/v1",
api_key=environ["LLMARINER_TOKEN"]
)
completion = client.chat.completions.create(
model="google-gemma-2b-it-q4_0",
messages=[
{"role": "user", "content": "What is k8s?"}
],
stream=True
)
for response in completion:
print(response.choices[0].delta.content, end="")
print("\n")
Please visit tutorials{.interpreted-text role=“doc”} to further exercise LLMariner.
Step 7: Clean up
Run the following command to destroy the EC2 instance.
terraform destroy -var-file=local.tfvars
2.1.3 - Set up a Playground on a CPU-only Kind Cluster
Set up the playground environment on a local kind cluster (CPU-only).
Following this guide provides you with a simplified, local LLMariner installation by using the Kind and Helm. You can use this simple LLMariner deployment to try out features without GPUs.
Warn
Playground environments are for experimentation use only. For a production-ready installation, please refere to the other installation guide.Before you begin
Before you can get started with the LLMariner deployment you must install:
Step 1: Clone the repository
To get started, clone the LLMariner repository.
git clone https://github.com/llmariner/llmariner.git
Step 2: Create a kind cluster
The installation files are in provision/dev/. Create a new Kubernetes cluster using kind by running:
cd provision/dev/
./create_cluster.sh single
Step 3: Install LLMariner
To install LLMariner using helmfile, run the following commands:
helmfile apply --skip-diff-on-install
Tips
You can filter the components to deploy using the--selector(-l) flag. For example, to filter out the monitoring components, set the -l tier!=monitoring flag. For deploying just the llmariner, use -l app=llmariner.2.1.4 - Install in a Single EKS Cluster
Install LLMariner in an EKS cluster with the standalone mode.
This page goes through the concrete steps to create an EKS cluster, create necessary resources, and install LLMariner. You can skip some of the steps if you have already made necessary installation/setup.
Step 1. Provision an EKS cluster
Step 1.1. Create a new cluster with Karpenter
Either follow the Karpenter getting started guide and create an EKS cluster with Karpenter, or run the following simplified installation steps.
export CLUSTER_NAME="llmariner-demo"
export AWS_DEFAULT_REGION="us-east-1"
export AWS_ACCOUNT_ID="$(aws sts get-caller-identity --query Account --output text)"
export KARPENTER_NAMESPACE="kube-system"
export KARPENTER_VERSION="1.0.1"
export K8S_VERSION="1.30"
export TEMPOUT="$(mktemp)"
curl -fsSL https://raw.githubusercontent.com/aws/karpenter-provider-aws/v"${KARPENTER_VERSION}"/website/content/en/preview/getting-started/getting-started-with-karpenter/cloudformation.yaml > "${TEMPOUT}" \
&& aws cloudformation deploy \
--stack-name "Karpenter-${CLUSTER_NAME}" \
--template-file "${TEMPOUT}" \
--capabilities CAPABILITY_NAMED_IAM \
--parameter-overrides "ClusterName=${CLUSTER_NAME}"
eksctl create cluster -f - <<EOF
---
apiVersion: eksctl.io/v1alpha5
kind: ClusterConfig
metadata:
name: ${CLUSTER_NAME}
region: ${AWS_DEFAULT_REGION}
version: "${K8S_VERSION}"
tags:
karpenter.sh/discovery: ${CLUSTER_NAME}
iam:
withOIDC: true
podIdentityAssociations:
- namespace: "${KARPENTER_NAMESPACE}"
serviceAccountName: karpenter
roleName: ${CLUSTER_NAME}-karpenter
permissionPolicyARNs:
- arn:aws:iam::${AWS_ACCOUNT_ID}:policy/KarpenterControllerPolicy-${CLUSTER_NAME}
iamIdentityMappings:
- arn: "arn:aws:iam::${AWS_ACCOUNT_ID}:role/KarpenterNodeRole-${CLUSTER_NAME}"
username: system:node:{{EC2PrivateDNSName}}
groups:
- system:bootstrappers
- system:nodes
managedNodeGroups:
- instanceType: m5.large
amiFamily: AmazonLinux2
name: ${CLUSTER_NAME}-ng
desiredCapacity: 2
minSize: 1
maxSize: 10
addons:
- name: eks-pod-identity-agent
EOF
# Create the service linked role if it does not exist. Ignore an already-exists error.
aws iam create-service-linked-role --aws-service-name spot.amazonaws.com || true
# Logout of helm registry to perform an unauthenticated pull against the public ECR.
helm registry logout public.ecr.aws
# Deploy Karpenter.
helm upgrade --install --wait \
--namespace "${KARPENTER_NAMESPACE}" \
--create-namespace \
karpenter oci://public.ecr.aws/karpenter/karpenter \
--version "${KARPENTER_VERSION}" \
--set "settings.clusterName=${CLUSTER_NAME}" \
--set "settings.interruptionQueue=${CLUSTER_NAME}" \
--set controller.resources.requests.cpu=1 \
--set controller.resources.requests.memory=1Gi \
--set controller.resources.limits.cpu=1 \
--set controller.resources.limits.memory=1Gi
Step 1.2. Provision GPU nodes
Once Karpenter is installed, we need to create an EC2NodeClass and a NodePool so that GPU nodes are provisioned. We configure blockDeviceMappings in the EC2NodeClass definition so that nodes have sufficient local storage to store model files.
export GPU_AMI_ID="$(aws ssm get-parameter --name /aws/service/eks/optimized-ami/${K8S_VERSION}/amazon-linux-2-gpu/recommended/image_id --query Parameter.Value --output text)"
cat << EOF | envsubst | kubectl apply -f -
apiVersion: karpenter.sh/v1
kind: NodePool
metadata:
name: default
spec:
template:
spec:
requirements:
- key: kubernetes.io/arch
operator: In
values: ["amd64"]
- key: kubernetes.io/os
operator: In
values: ["linux"]
- key: karpenter.sh/capacity-type
operator: In
values: ["on-demand"]
- key: karpenter.k8s.aws/instance-family
operator: In
values: ["g5"]
nodeClassRef:
group: karpenter.k8s.aws
kind: EC2NodeClass
name: default
expireAfter: 720h
disruption:
consolidationPolicy: WhenEmptyOrUnderutilized
consolidateAfter: 1m
---
apiVersion: karpenter.k8s.aws/v1
kind: EC2NodeClass
metadata:
name: default
spec:
amiFamily: AL2
role: "KarpenterNodeRole-${CLUSTER_NAME}"
subnetSelectorTerms:
- tags:
karpenter.sh/discovery: "${CLUSTER_NAME}"
securityGroupSelectorTerms:
- tags:
karpenter.sh/discovery: "${CLUSTER_NAME}"
amiSelectorTerms:
- id: "${GPU_AMI_ID}"
blockDeviceMappings:
- deviceName: /dev/xvda
ebs:
deleteOnTermination: true
encrypted: true
volumeSize: 256Gi
volumeType: gp3
EOF
Step 1.3. Install Nvidia GPU Operator
Nvidia GPU Operator is required to install the device plugin and make GPU resources visible in the K8s cluster. Run:
helm repo add nvidia https://helm.ngc.nvidia.com/nvidia
helm repo update
helm upgrade --install --wait \
--namespace nvidia \
--create-namespace \
gpu-operator nvidia/gpu-operator \
--set cdi.enabled=true \
--set driver.enabled=false \
--set toolkit.enabled=false
Step 1.4. Install an ingress controller
An ingress controller is required to route HTTP/HTTPS requests to the LLMariner components. Any ingress controller works, and you can skip this step if your EKS cluster already has an ingress controller.
Here is an example that installs Kong and make the ingress controller reachable via AWS loadbalancer:
helm repo add kong https://charts.konghq.com
helm repo update
helm upgrade --install --wait \
--namespace kong \
--create-namespace \
kong-proxy kong/kong \
--set proxy.annotations.service.beta.kubernetes.io/aws-load-balancer-connection-idle-timeout=300 \
--set ingressController.installCRDs=false \
--set fullnameOverride=false
Step 2. Create an RDS instance
We will create an RDS in the same VPC as the EKS cluster so that it can be reachable from the LLMariner components. Here are example commands for creating a DB subnet group:
export DB_SUBNET_GROUP_NAME="llmariner-demo-db-subnet"
export EKS_SUBNET_IDS=$(aws eks describe-cluster --name "${CLUSTER_NAME}" | jq '.cluster.resourcesVpcConfig.subnetIds | join(" ")' --raw-output)
export EKS_SUBNET_ID0=$(echo ${EKS_SUBNET_IDS} | cut -d' ' -f1)
export EKS_SUBNET_ID1=$(echo ${EKS_SUBNET_IDS} | cut -d' ' -f2)
aws rds create-db-subnet-group \
--db-subnet-group-name "${DB_SUBNET_GROUP_NAME}" \
--db-subnet-group-description "LLMariner Demo" \
--subnet-ids "${EKS_SUBNET_ID0}" "${EKS_SUBNET_ID1}"
and an RDS instance:
export DB_INSTANCE_ID="llmariner-demo"
export POSTGRES_USER="admin_user"
export POSTGRES_PASSWORD="secret_password"
export EKS_SECURITY_GROUP_ID=$(aws eks describe-cluster --name "${CLUSTER_NAME}" | jq '.cluster.resourcesVpcConfig.clusterSecurityGroupId' --raw-output)
aws rds create-db-instance \
--db-instance-identifier "${DB_INSTANCE_ID}" \
--db-instance-class db.t3.small \
--engine postgres \
--allocated-storage 10 \
--storage-encrypted \
--master-username "${POSTGRES_USER}" \
--master-user-password "${POSTGRES_PASSWORD}" \
--vpc-security-group-ids "${EKS_SECURITY_GROUP_ID}" \
--db-subnet-group-name "${DB_SUBNET_GROUP_NAME}"
You can run the following command to check the provisioning status.
aws rds describe-db-instances --db-instance-identifier "${DB_INSTANCE_ID}" | jq '.DBInstances[].DBInstanceStatus'
Once the RDS instance is fully provisioned and its status becomes available, obtain the endpoint information for later use.
export POSTGRES_ADDR=$(aws rds describe-db-instances --db-instance-identifier "${DB_INSTANCE_ID}" | jq '.DBInstances[].Endpoint.Address' --raw-output)
export POSTGRES_PORT=$(aws rds describe-db-instances --db-instance-identifier "${DB_INSTANCE_ID}" | jq '.DBInstances[].Endpoint.Port' --raw-output)
You can verify if the DB instance is reachable from the EKS cluster by running the psql command:
kubectl run psql --image jbergknoff/postgresql-client --env="PGPASSWORD=${POSTGRES_PASSWORD}" -- -h "${POSTGRES_ADDR}" -U "${POSTGRES_USER}" -p "${POSTGRES_PORT}" -d template1 -c "select now();"
kubectl logs psql
kubectl delete pods psql
Note
LLMariner will create additional databases on the fly for each API service (e.g.,job_manager, model_manager). You can see all created databases by running SELECT count(datname) FROM pg_database;.Step 3. Create an S3 bucket
We will create an S3 bucket where model files are stored. Here is an example
# Please change the bucket name to something else.
export S3_BUCKET_NAME="llmariner-demo"
export S3_REGION="us-east-1"
aws s3api create-bucket --bucket "${S3_BUCKET_NAME}" --region "${S3_REGION}"
If you want to set up Milvus for RAG, please create another S3 bucket for Milvus:
# Please change the bucket name to something else.
export MILVUS_S3_BUCKET_NAME="llmariner-demo-milvus"
aws s3api create-bucket --bucket "${MILVUS_S3_BUCKET_NAME}" --region "${S3_REGION}"
Pods running in the EKS cluster need to be able to access the S3 bucket. We will create an IAM role for service account for that.
export LLMARINER_NAMESPACE=llmariner
export LLMARINER_POLICY="LLMarinerPolicy"
export LLMARINER_SERVICE_ACCOUNT_NAME="llmariner"
export LLMARINER_ROLE="LLMarinerRole"
cat << EOF | envsubst > policy.json
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"s3:PutObject",
"s3:GetObject",
"s3:DeleteObject",
"s3:ListBucket"
],
"Resource": [
"arn:aws:s3:::${S3_BUCKET_NAME}/*",
"arn:aws:s3:::${S3_BUCKET_NAME}",
"arn:aws:s3:::${MILVUS_S3_BUCKET_NAME}/*",
"arn:aws:s3:::${MILVUS_S3_BUCKET_NAME}"
]
}
]
}
EOF
aws iam create-policy --policy-name "${LLMARINER_POLICY}" --policy-document file://policy.json
eksctl create iamserviceaccount \
--name "${LLMARINER_SERVICE_ACCOUNT_NAME}" \
--namespace "${LLMARINER_NAMESPACE}" \
--cluster "${CLUSTER_NAME}" \
--role-name "${LLMARINER_ROLE}" \
--attach-policy-arn "arn:aws:iam::${AWS_ACCOUNT_ID}:policy/${LLMARINER_POLICY}" --approve
Step 4. Install Milvus
Install Milvus as it is used a backend vector database for RAG.
Milvus creates Persistent Volumes. Follow https://docs.aws.amazon.com/eks/latest/userguide/ebs-csi.html and install EBS CSI driver.
export EBS_CSI_DRIVER_ROLE="AmazonEKS_EBS_CSI_DriverRole"
eksctl create iamserviceaccount \
--name ebs-csi-controller-sa \
--namespace kube-system \
--cluster "${CLUSTER_NAME}" \
--role-name "${EBS_CSI_DRIVER_ROLE}" \
--role-only \
--attach-policy-arn arn:aws:iam::aws:policy/service-role/AmazonEBSCSIDriverPolicy \
--approve
eksctl create addon \
--cluster "${CLUSTER_NAME}" \
--name aws-ebs-csi-driver \
--version latest \
--service-account-role-arn "arn:aws:iam::${AWS_ACCOUNT_ID}:role/${EBS_CSI_DRIVER_ROLE}" \
--force
Then install the Helm chart. Milvus requires access to the S3 bucket. To use the same service account created above, we deploy Milvus in the same namespace as LLMariner.
cat << EOF | envsubst > milvus-values.yaml
cluster:
enabled: false
etcd:
replicaCount: 1
persistence:
storageClass: gp2 # Use gp3 if available
pulsarv3:
enabled: false
minio:
enabled: false
standalone:
persistence:
persistentVolumeClaim:
storageClass: gp2 # Use gp3 if available
size: 10Gi
serviceAccount:
create: false
name: "${LLMARINER_SERVICE_ACCOUNT_NAME}"
externalS3:
enabled: true
host: s3.us-east-1.amazonaws.com
port: 443
useSSL: true
bucketName: "${MILVUS_S3_BUCKET_NAME}"
region: us-east-1
useIAM: true
cloudProvider: aws
iamEndpoint: ""
logLevel: info
EOF
helm repo add zilliztech https://zilliztech.github.io/milvus-helm/
helm repo update
helm upgrade --install --wait \
--namespace "${LLMARINER_NAMESPACE}" \
--create-namespace \
milvus zilliztech/milvus \
-f milvus-values.yaml
Please see the Milvus installation document and the Helm chart for other installation options.
Set the environmental variables so that LLMariner can later access the Postgres database.
export MILVUS_ADDR=milvus.llmariner.svc.cluster.local
Step 5. Install LLMariner
Run the following command to set up a values.yaml and install LLMariner with Helm.
# Set the endpoint URL of LLMariner. Please change if you are using a different ingress controller.
export INGRESS_CONTROLLER_URL=http://$(kubectl get services -n kong kong-proxy-kong-proxy -o jsonpath='{.status.loadBalancer.ingress[0].hostname}')
export POSTGRES_SECRET_NAME="db-secret"
cat << EOF | envsubst > llmariner-values.yaml
global:
# This is an ingress configuration with Kong. Please change if you are using a different ingress controller.
ingress:
ingressClassName: kong
# The URL of the ingress controller. this can be a port-forwarding URL (e.g., http://localhost:8080) if there is
# no URL that is reachable from the outside of the EKS cluster.
controllerUrl: "${INGRESS_CONTROLLER_URL}"
annotations:
# To remove the buffering from the streaming output of chat completion.
konghq.com/response-buffering: "false"
database:
host: "${POSTGRES_ADDR}"
port: ${POSTGRES_PORT}
username: "${POSTGRES_USER}"
ssl:
mode: require
createDatabase: true
databaseSecret:
name: "${POSTGRES_SECRET_NAME}"
key: password
objectStore:
s3:
bucket: "${S3_BUCKET_NAME}"
region: "${S3_REGION}"
endpointUrl: ""
prepare:
database:
createSecret: true
secret:
password: "${POSTGRES_PASSWORD}"
dex-server:
staticPasswords:
- email: admin@example.com
# bcrypt hash of the string: $(echo password | htpasswd -BinC 10 admin | cut -d: -f2)
hash: "\$2a\$10\$2b2cU8CPhOTaGrs1HRQuAueS7JTT5ZHsHSzYiFPm1leZck7Mc8T4W"
username: admin-user
userID: admin-id
file-manager-server:
serviceAccount:
create: false
name: "${LLMARINER_SERVICE_ACCOUNT_NAME}"
inference-manager-engine:
serviceAccount:
create: false
name: "${LLMARINER_SERVICE_ACCOUNT_NAME}"
model:
default:
runtimeName: vllm
preloaded: true
resources:
limits:
nvidia.com/gpu: 1
overrides:
meta-llama/Meta-Llama-3.1-8B-Instruct-q4_0:
contextLength: 16384
google/gemma-2b-it-q4_0:
runtimeName: ollama
resources:
limits:
nvidia.com/gpu: 0
sentence-transformers/all-MiniLM-L6-v2-f16:
runtimeName: ollama
resources:
limits:
nvidia.com/gpu: 0
inference-manager-server:
service:
annotations:
# These annotations are only meaningful for Kong ingress controller to extend the timeout.
konghq.com/connect-timeout: "360000"
konghq.com/read-timeout: "360000"
konghq.com/write-timeout: "360000"
job-manager-dispatcher:
serviceAccount:
create: false
name: "${LLMARINER_SERVICE_ACCOUNT_NAME}"
notebook:
# Used to set the base URL of the API endpoint. This can be same as global.ingress.controllerUrl
# if the URL is reachable from the inside cluster. Otherwise you can change this to the
# to the URL of the ingress controller that is reachable inside the K8s cluster.
llmarinerBaseUrl: "${INGRESS_CONTROLLER_URL}/v1"
model-manager-loader:
serviceAccount:
create: false
name: "${LLMARINER_SERVICE_ACCOUNT_NAME}"
baseModels:
- meta-llama/Meta-Llama-3.1-8B-Instruct-q4_0
- google/gemma-2b-it-q4_0
- sentence-transformers/all-MiniLM-L6-v2-f16
# Required when RAG is used.
vector-store-manager-server:
serviceAccount:
create: false
name: "${LLMARINER_SERVICE_ACCOUNT_NAME}"
vectorDatabase:
host: "${MILVUS_ADDR}"
llmEngineAddr: ollama-sentence-transformers-all-minilm-l6-v2-f16:11434
EOF
helm upgrade --install \
--namespace llmariner \
--create-namespace \
llmariner oci://public.ecr.aws/cloudnatix/llmariner-charts/llmariner \
-f llmariner-values.yaml
Note
Starting from Helm v3.8.0, the OCI registry is supported by default. If you are using an older version, please upgrade to v3.8.0 or later. For more details, please refer to Helm OCI-based registries.Note
If you are getting a 403 forbidden error, please trydocker logout public.ecr.aws. Please see AWS document for more details.If you would like to install only the control-plane components or the worker-plane components, please see multi_cluster_deployment{.interpreted-text role=“doc”}.
Step 6. Verify the installation
You can verify the installation by sending sample chat completion requests.
Note, if you have used LLMariner in other cases before you may need to delete the previous config by running rm -rf ~/.config/llmariner
The default login user name is admin@example.com and the password is
password. You can change this by updating the Dex configuration
(link).
echo "This is your endpoint URL: ${INGRESS_CONTROLLER_URL}/v1"
llma auth login
# Type the above endpoint URL.
llma models list
llma chat completions create --model google-gemma-2b-it-q4_0 --role user --completion "what is k8s?"
llma chat completions create --model meta-llama-Meta-Llama-3.1-8B-Instruct-q4_0 --role user --completion "hello"
Optional: Monitor GPU utilization
If you would like to install Prometheus and Grafana to see GPU utilization, run:
# Add Prometheus
cat <<EOF > prom-scrape-configs.yaml
- job_name: nvidia-dcgm
scrape_interval: 5s
static_configs:
- targets: ['nvidia-dcgm-exporter.nvidia.svc:9400']
- job_name: inference-manager-engine-metrics
scrape_interval: 5s
static_configs:
- targets: ['inference-manager-server-http.llmariner.svc:8083']
EOF
helm repo add prometheus-community https://prometheus-community.github.io/helm-charts
helm repo update
helm upgrade --install --wait \
--namespace monitoring \
--create-namespace \
--set-file extraScrapeConfigs=prom-scrape-configs.yaml \
prometheus prometheus-community/prometheus
# Add Grafana with DCGM dashboard
cat <<EOF > grafana-values.yaml
datasources:
datasources.yaml:
apiVersion: 1
datasources:
- name: Prometheus
type: prometheus
url: http://prometheus-server
isDefault: true
dashboardProviders:
dashboardproviders.yaml:
apiVersion: 1
providers:
- name: 'default'
orgId: 1
folder: 'default'
type: file
disableDeletion: true
editable: true
options:
path: /var/lib/grafana/dashboards/standard
dashboards:
default:
nvidia-dcgm-exporter:
gnetId: 12239
datasource: Prometheus
EOF
helm repo add grafana https://grafana.github.io/helm-charts
helm repo update
helm upgrade --install --wait \
--namespace monitoring \
--create-namespace \
-f grafana-values.yaml \
grafana grafana/grafana
Optional: Enable TLS
First follow the cert-manager installation document and install cert-manager to your K8s cluster if you don’t have one. Then create a ClusterIssuer for your domain. Here is an example manifest that uses Let's Encrypt.
apiVersion: cert-manager.io/v1
kind: ClusterIssuer
metadata:
name: letsencrypt
spec:
acme:
server: https://acme-v02.api.letsencrypt.org/directory
email: user@mydomain.com
privateKeySecretRef:
name: letsencrypt
solvers:
- http01:
ingress:
ingressClassName: kong
- selector:
dnsZones:
- llm.mydomain.com
dns01:
...
Then you can add the following to values.yaml of LLMariner to enable TLS.
global:
ingress:
annotations:
cert-manager.io/cluster-issuer: letsencrypt
tls:
hosts:
- api.llm.mydomain.com
secretName: api-tls
The ingresses created from the Helm chart will have the following annotation and spec:
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
annotations:
cert-manager.io/cluster-issuer: letsencrypt
...
spec:
tls:
- hosts:
- api.llm.mydomain.com
secretName: api-tls
...
2.1.5 - Install in a Single On-premise Cluster
Install LLMariner in an on-premise Kubernetes cluster with the standalone mode.
This page goes through the concrete steps to install LLMariner on a on-premise K8s cluster (or a local K8s cluster). You can skip some of the steps if you have already made necessary installation/setup.
Note
Installation of Postgres, MinIO, SeaweedFS, and Milvus are just example purposes, and they are not intended for the production usage. Please configure based on your requirements if you want to use LLMariner for your production environment.Step 1. Install Nvidia GPU Operator
Nvidia GPU Operator is required to install the device plugin and make GPU resources visible in the K8s cluster. Run:
helm repo add nvidia https://helm.ngc.nvidia.com/nvidia
helm repo update
helm upgrade --install --wait \
--namespace nvidia \
--create-namespace \
gpu-operator nvidia/gpu-operator \
--set cdi.enabled=true \
--set driver.enabled=false \
--set toolkit.enabled=false
Step 2. Install an ingress controller
An ingress controller is required to route HTTP/HTTPS requests to the LLMariner components. Any ingress controller works, and you can skip this step if your EKS cluster already has an ingress controller.
Here is an example that installs Kong and make the ingress controller:
helm repo add kong https://charts.konghq.com
helm repo update
cat <<EOF > kong-values.yaml
proxy:
type: NodePort
http:
hostPort: 80
tls:
hostPort: 443
annotations:
service.beta.kubernetes.io/aws-load-balancer-connection-idle-timeout: "300"
nodeSelector:
ingress-ready: "true"
tolerations:
- key: node-role.kubernetes.io/control-plane
operator: Equal
effect: NoSchedule
- key: node-role.kubernetes.io/master
operator: Equal
effect: NoSchedule
fullnameOverride: kong
EOF
helm upgrade --install --wait \
--namespace kong \
--create-namespace \
kong-proxy kong/kong \
-f kong-values.yaml
Step 3. Install a Postgres database
Run the following to deploy an Postgres deployment:
export POSTGRES_USER="admin_user"
export POSTGRES_PASSWORD="secret_password"
helm upgrade --install --wait \
--namespace postgres \
--create-namespace \
postgres oci://registry-1.docker.io/bitnamicharts/postgresql \
--set nameOverride=postgres \
--set auth.database=ps_db \
--set auth.username="${POSTGRES_USER}" \
--set auth.password="${POSTGRES_PASSWORD}"
Set the environmental variables so that LLMariner can later access the Postgres database.
export POSTGRES_ADDR=postgres.postgres
export POSTGRES_PORT=5432
Step 4. Install an S3-compatible object store
LLMariner requires an S3-compatible object store such as MinIO or SeaweedFS.
First set environmental variables to specify installation configuration:
# Bucket name and the dummy region.
export S3_BUCKET_NAME=llmariner
export S3_REGION=dummy
# Credentials for accessing the S3 bucket.
export AWS_ACCESS_KEY_ID=llmariner-key
export AWS_SECRET_ACCESS_KEY=llmariner-secret
Then install an object store. Here are the example installation commands for MinIO and SeaweedFS.
helm upgrade --install --wait \
--namespace minio \
--create-namespace \
minio oci://registry-1.docker.io/bitnamicharts/minio \
--set auth.rootUser=minioadmin \
--set auth.rootPassword=minioadmin \
--set defaultBuckets="${S3_BUCKET_NAME}"
kubectl port-forward -n minio service/minio 9001 &
# Wait until the port-forwarding connection is established.
sleep 5
# Obtain the cookie and store in cookies.txt.
curl \
http://localhost:9001/api/v1/login \
--cookie-jar cookies.txt \
--request POST \
--header 'Content-Type: application/json' \
--data @- << EOF
{
"accessKey": "minioadmin",
"secretKey": "minioadmin"
}
EOF
# Create a new API key.
curl \
http://localhost:9001/api/v1/service-account-credentials \
--cookie cookies.txt \
--request POST \
--header "Content-Type: application/json" \
--data @- << EOF >/dev/null
{
"name": "LLMariner",
"accessKey": "$AWS_ACCESS_KEY_ID",
"secretKey": "$AWS_SECRET_ACCESS_KEY",
"description": "",
"comment": "",
"policy": "",
"expiry": null
}
EOF
rm cookies.txt
kill %1
kubectl create namespace seaweedfs
# Create a secret.
# See https://github.com/seaweedfs/seaweedfs/wiki/Amazon-S3-API#public-access-with-anonymous-download for details.
cat <<EOF > s3-config.json
{
"identities": [
{
"name": "me",
"credentials": [
{
"accessKey": "${AWS_ACCESS_KEY_ID}",
"secretKey": "${AWS_SECRET_ACCESS_KEY}"
}
],
"actions": [
"Admin",
"Read",
"ReadAcp",
"List",
"Tagging",
"Write",
"WriteAcp"
]
}
]
}
EOF
kubectl create secret generic -n seaweedfs seaweedfs --from-file=s3-config.json
rm s3-config.json
# deploy seaweedfs
cat << EOF | kubectl apply -n seaweedfs -f -
apiVersion: v1
kind: PersistentVolume
metadata:
name: seaweedfs-volume
labels:
type: local
app: seaweedfs
spec:
storageClassName: manual
capacity:
storage: 500Mi
accessModes:
- ReadWriteMany
hostPath:
path: /data/seaweedfs
---
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: seaweedfs-volume-claim
labels:
app: seaweedfs
spec:
storageClassName: manual
accessModes:
- ReadWriteMany
resources:
requests:
storage: 500Mi
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: seaweedfs
spec:
replicas: 1
selector:
matchLabels:
app: seaweedfs
template:
metadata:
labels:
app: seaweedfs
spec:
containers:
- name: seaweedfs
image: chrislusf/seaweedfs
args:
- server -s3 -s3.config=/etc/config/s3-config.json -dir=/data
ports:
- name: master
containerPort: 9333
protocol: TCP
- name: s3
containerPort: 8333
protocol: TCP
volumeMounts:
- name: seaweedfsdata
mountPath: /data
- name: config
mountPath: /etc/config
volumes:
- name: seaweedfsdata
persistentVolumeClaim:
claimName: seaweedfs-volume-claim
- name: config
secret:
secretName: seaweedfs
---
apiVersion: v1
kind: Service
metadata:
name: seaweedfs
labels:
app: seaweedfs
spec:
type: NodePort
ports:
- port: 9333
targetPort: master
protocol: TCP
name: master
nodePort: 31238
- port: 8333
targetPort: s3
protocol: TCP
name: s3
nodePort: 31239
selector:
app: seaweedfs
EOF
kubectl wait --timeout=60s --for=condition=ready pod -n seaweedfs -l app=seaweedfs
kubectl port-forward -n seaweedfs service/seaweedfs 8333 &
# Wait until the port-forwarding connection is established.
sleep 5
# Create the bucket.
aws --endpoint-url http://localhost:8333 s3 mb s3://${S3_BUCKET_NAME}
kill %1
Then set environmental variable S3_ENDPOINT_URL to the URL of the object store. The URL should be accessible from LLMariner pods that will run on the same cluster.
export S3_ENDPOINT_URL=http://minio.minio:9000
export S3_ENDPOINT_URL=http://seaweedfs.seaweedfs:8333
Step 5. Install Milvus
Install Milvus as it is used a backend vector database for RAG.
cat << EOF > milvus-values.yaml
cluster:
enabled: false
etcd:
enabled: false
pulsar:
enabled: false
minio:
enabled: false
tls:
enabled: false
extraConfigFiles:
user.yaml: |+
etcd:
use:
embed: true
data:
dir: /var/lib/milvus/etcd
common:
storageType: local
EOF
helm repo add zilliztech https://zilliztech.github.io/milvus-helm/
helm repo update
helm upgrade --install --wait \
--namespace milvus \
--create-namespace \
milvus zilliztech/milvus \
-f milvus-values.yaml
Set the environmental variables so that LLMariner can later access the Postgres database.
export MILVUS_ADDR=milvus.milvus
Step 6. Install LLMariner
Run the following command to set up a values.yaml and install LLMariner with Helm.
# Set the endpoint URL of LLMariner. Please change if you are using a different ingress controller.
export INGRESS_CONTROLLER_URL=http://localhost:8080
cat << EOF | envsubst > llmariner-values.yaml
global:
# This is an ingress configuration with Kong. Please change if you are using a different ingress controller.
ingress:
ingressClassName: kong
# The URL of the ingress controller. this can be a port-forwarding URL (e.g., http://localhost:8080) if there is
# no URL that is reachable from the outside of the EKS cluster.
controllerUrl: "${INGRESS_CONTROLLER_URL}"
annotations:
# To remove the buffering from the streaming output of chat completion.
konghq.com/response-buffering: "false"
database:
host: "${POSTGRES_ADDR}"
port: ${POSTGRES_PORT}
username: "${POSTGRES_USER}"
ssl:
mode: disable
createDatabase: true
databaseSecret:
name: postgres
key: password
objectStore:
s3:
endpointUrl: "${S3_ENDPOINT_URL}"
bucket: "${S3_BUCKET_NAME}"
region: "${S3_REGION}"
awsSecret:
name: aws
accessKeyIdKey: accessKeyId
secretAccessKeyKey: secretAccessKey
prepare:
database:
createSecret: true
secret:
password: "${POSTGRES_PASSWORD}"
objectStore:
createSecret: true
secret:
accessKeyId: "${AWS_ACCESS_KEY_ID}"
secretAccessKey: "${AWS_SECRET_ACCESS_KEY}"
dex-server:
staticPasswords:
- email: admin@example.com
# bcrypt hash of the string: $(echo password | htpasswd -BinC 10 admin | cut -d: -f2)
hash: "\$2a\$10\$2b2cU8CPhOTaGrs1HRQuAueS7JTT5ZHsHSzYiFPm1leZck7Mc8T4W"
username: admin-user
userID: admin-id
inference-manager-engine:
model:
default:
runtimeName: vllm
preloaded: true
resources:
limits:
nvidia.com/gpu: 1
overrides:
meta-llama/Meta-Llama-3.1-8B-Instruct-q4_0:
contextLength: 16384
google/gemma-2b-it-q4_0:
runtimeName: ollama
resources:
limits:
nvidia.com/gpu: 0
sentence-transformers/all-MiniLM-L6-v2-f16:
runtimeName: ollama
resources:
limits:
nvidia.com/gpu: 0
inference-manager-server:
service:
annotations:
# These annotations are only meaningful for Kong ingress controller to extend the timeout.
konghq.com/connect-timeout: "360000"
konghq.com/read-timeout: "360000"
konghq.com/write-timeout: "360000"
job-manager-dispatcher:
serviceAccount:
create: false
name: "${LLMARINER_SERVICE_ACCOUNT_NAME}"
notebook:
# Used to set the base URL of the API endpoint. This can be same as global.ingress.controllerUrl
# if the URL is reachable from the inside cluster. Otherwise you can change this to the
# to the URL of the ingress controller that is reachable inside the K8s cluster.
llmarinerBaseUrl: "${INGRESS_CONTROLLER_URL}/v1"
model-manager-loader:
baseModels:
- meta-llama/Meta-Llama-3.1-8B-Instruct-q4_0
- google/gemma-2b-it-q4_0
- sentence-transformers/all-MiniLM-L6-v2-f16
# Required when RAG is used.
vector-store-manager-server:
vectorDatabase:
host: "${MILVUS_ADDR}"
llmEngineAddr: ollama-sentence-transformers-all-minilm-l6-v2-f16:11434
EOF
helm upgrade --install \
--namespace llmariner \
--create-namespace \
llmariner oci://public.ecr.aws/cloudnatix/llmariner-charts/llmariner \
-f llmariner-values.yaml
Note
Starting from Helm v3.8.0, the OCI registry is supported by default. If you are using an older version, please upgrade to v3.8.0 or later. For more details, please refer to Helm OCI-based registries.Note
If you are getting a 403 forbidden error, please trydocker logout public.ecr.aws. Please see AWS document for more details.If you would like to install only the control-plane components or the worker-plane components, please see multi_cluster_deployment{.interpreted-text role=“doc”}.
Step 7. Verify the installation
You can verify the installation by sending sample chat completion requests.
Note, if you have used LLMariner in other cases before you may need to delete the previous config by running rm -rf ~/.config/llmariner
The default login user name is admin@example.com and the password is
password. You can change this by updating the Dex configuration
(link).
echo "This is your endpoint URL: ${INGRESS_CONTROLLER_URL}/v1"
llma auth login
# Type the above endpoint URL.
llma models list
llma chat completions create --model google-gemma-2b-it-q4_0 --role user --completion "what is k8s?"
llma chat completions create --model meta-llama-Meta-Llama-3.1-8B-Instruct-q4_0 --role user --completion "hello"
Optional: Monitor GPU utilization
If you would like to install Prometheus and Grafana to see GPU utilization, run:
# Add Prometheus
cat <<EOF > prom-scrape-configs.yaml
- job_name: nvidia-dcgm
scrape_interval: 5s
static_configs:
- targets: ['nvidia-dcgm-exporter.nvidia.svc:9400']
- job_name: inference-manager-engine-metrics
scrape_interval: 5s
static_configs:
- targets: ['inference-manager-server-http.llmariner.svc:8083']
EOF
helm repo add prometheus-community https://prometheus-community.github.io/helm-charts
helm repo update
helm upgrade --install --wait \
--namespace monitoring \
--create-namespace \
--set-file extraScrapeConfigs=prom-scrape-configs.yaml \
prometheus prometheus-community/prometheus
# Add Grafana with DCGM dashboard
cat <<EOF > grafana-values.yaml
datasources:
datasources.yaml:
apiVersion: 1
datasources:
- name: Prometheus
type: prometheus
url: http://prometheus-server
isDefault: true
dashboardProviders:
dashboardproviders.yaml:
apiVersion: 1
providers:
- name: 'default'
orgId: 1
folder: 'default'
type: file
disableDeletion: true
editable: true
options:
path: /var/lib/grafana/dashboards/standard
dashboards:
default:
nvidia-dcgm-exporter:
gnetId: 12239
datasource: Prometheus
EOF
helm repo add grafana https://grafana.github.io/helm-charts
helm repo update
helm upgrade --install --wait \
--namespace monitoring \
--create-namespace \
-f grafana-values.yaml \
grafana grafana/grafana
Optional: Enable TLS
First follow the cert-manager installation document and install cert-manager to your K8s cluster if you don’t have one. Then create a ClusterIssuer for your domain. Here is an example manifest that uses Let's Encrypt.
apiVersion: cert-manager.io/v1
kind: ClusterIssuer
metadata:
name: letsencrypt
spec:
acme:
server: https://acme-v02.api.letsencrypt.org/directory
email: user@mydomain.com
privateKeySecretRef:
name: letsencrypt
solvers:
- http01:
ingress:
ingressClassName: kong
- selector:
dnsZones:
- llm.mydomain.com
dns01:
...
Then you can add the following to values.yaml of LLMariner to enable TLS.
global:
ingress:
annotations:
cert-manager.io/cluster-issuer: letsencrypt
tls:
hosts:
- api.llm.mydomain.com
secretName: api-tls
The ingresses created from the Helm chart will have the following annotation and spec:
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
annotations:
cert-manager.io/cluster-issuer: letsencrypt
...
spec:
tls:
- hosts:
- api.llm.mydomain.com
secretName: api-tls
...
2.1.6 - Install across Multiple Clusters
Install LLMarinr across multiple Kubernetes clusters.
LLMariner deploys Kubernetes deployments to provision the LLM stack. In a typical configuration, all the services are deployed into a single Kubernetes cluster, but you can also deploy these services on multiple Kubernetes clusters. For example, you can deploy a control plane component in a CPU K8s cluster and deploy the rest of the components in GPU compute clusters.
LLMariner can be deployed into multiple GPU clusters, and the clusters can span across multiple cloud providers (including GPU specific clouds like CoreWeave) and on-prem.
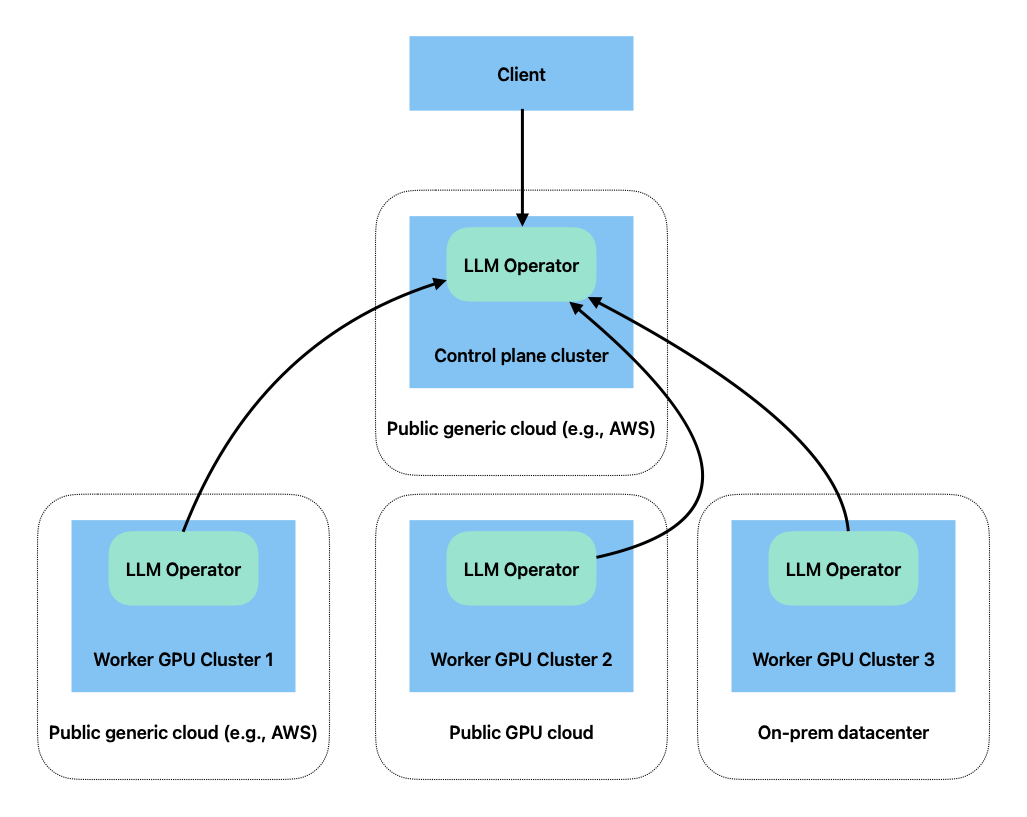
Deploying Control Plane Components
You can deploy only Control Plane components by specifying additional parameters the LLMariner helm chart.
In the values.yaml, you need to set tag.worker to false, global.workerServiceIngress.create to true, and set other values so that an ingress and a service are created to receive requests from worker nodes.
Here is an example values.yaml.
tags:
worker: false
global:
ingress:
ingressClassName: kong
controllerUrl: https://api.mydomain.com
annotations:
cert-manager.io/cluster-issuer: letsencrypt
konghq.com/response-buffering: "false"
# Enable TLS for the ingresses.
tls:
hosts:
- api.llm.mydomain.com
secretName: api-tls
# Create ingress for gRPC requests coming from worker clusters.
workerServiceIngress:
create: true
annotations:
cert-manager.io/cluster-issuer: letsencrypt
konghq.com/protocols: grpc,grpcs
workerServiceGrpcService:
annotations:
konghq.com/protocol: grpc
# Create a separate load balancer for gRPC streaming requests from inference-manager-engine.
inference-manager-server:
workerServiceTls:
enable: true
secretName: inference-cert
workerServiceGrpcService:
type: LoadBalancer
port: 443
annotations:
external-dns.alpha.kubernetes.io/hostname: inference.llm.mydomain.com
# Create a separate load balancer for HTTPS requests from session-manager-agent.
session-manager-server:
workerServiceTls:
enable: true
secretName: session-cert
workerServiceHttpService:
type: LoadBalancer
port: 443
externalTrafficPolicy: Local
annotations:
service.beta.kubernetes.io/aws-load-balancer-type: "nlb"
external-dns.alpha.kubernetes.io/hostname: session.llm.mydomain.com
Deploying Worker Components
To deploy LLMariner to a worker GPU cluster, you first need to obtain a registration key for the cluster.
llma admin clusters register <cluster-name>
The following is an example command that sets the registration key to the environment variable.
REGISTRATION_KEY=$(llma admin clusters register <cluster-name> | sed -n 's/.*Registration Key: "\([^"]*\)".*/\1/p')
The command generates a new registration key.
Then you need to make LLMariner worker components to use the registration key when making gRPC calls to the control plane.
To make that happen, you first need to create a K8s secret.
REGISTRATION_KEY=clusterkey-...
kubectl create secret generic \
-n llmariner \
cluster-registration-key \
--from-literal=regKey="${REGISTRATION_KEY}"
The secret needs to be created in a namespace where LLMariner will be deployed.
When installing the Helm chart for the worker components, you need to specify addition configurations in values.yaml. Here is an example.
tags:
control-plane: false
global:
objectStore:
s3:
endpointUrl: <S3 endpoint>
region: <S3 regiona>
bucket: <S3 bucket name>
awsSecret:
name: aws
accessKeyIdKey: accessKeyId
secretAccessKeyKey: secretAccessKey
worker:
controlPlaneAddr: api.llm.mydomain.com:443
tls:
enable: true
registrationKeySecret:
name: cluster-registration-key
key: regKey
inference-manager-engine:
inferenceManagerServerWorkerServiceAddr: inference.llm.mydomain.com:443
job-manager-dispatcher:
notebook:
llmarinerBaseUrl: https://api.llm.mydomain.com/v1
session-manager-agent:
sessionManagerServerWorkerServiceAddr: session.llm.mydomain.com:443
model-manager-loader:
baseModels:
- <model name, e.g. google/gemma-2b-it-q4_0>
2.1.7 - Hosted Control Plane
Install just the worker plane and use it with the hosted control plane.
CloudNatix provides a hosted control plane of LLMariner.
Note
Work-in-progress. This is not fully ready yet, and the terms and conditions are subject to change as we might limit the usage based on the number of API calls or the number of GPU nodes.CloudNatix provides a hosted control plane of LLMariner. End users can use the full functionality of LLMariner just by registering their worker GPU clusters to this hosted control plane.
Step 1. Create a CloudNatix account
Create a CloudNatix account if you haven't. Please visit https://app.cloudnatix.com. You can click one of the "Sign in or sign up" buttons for SSO login or you can click "Sign up" at the bottom for the email & password login.
Step 2. Deploy the worker plane components
Deploy the worker plane components of LLMariner into your GPU cluster.
The API endpoint of the hosted control plane is https://api.llm.cloudnatix.com/v1.
Step 2.1 Generate a cluster registration key
A cluster registration key is required to register your cluster.
If you prefer GUI, visit https://app.llm.cloudnatix.com/app/admin and click “Add worker cluster”.
If you prefer CLI, run llma auth login and use the above for the endpoint URL. Then run:
llma admin clusters register <cluster-name>
Then create a secret containing the registration key.
REGISTRATION_KEY=clusterkey-...
kubectl create secret generic \
-n llmariner \
cluster-registration-key \
--from-literal=regKey="${REGISTRATION_KEY}"
Step 2.2 Create a k8s secret for Hugging Face API key (optional)
If you want to download models from Hugging Face, create a k8s secret with the following command:
HUGGING_FACE_HUB_TOKEN=...
kubectl create secret generic \
huggingface-key \
-n llmariner \
--from-literal=apiKey=${HUGGING_FACE_HUB_TOKEN}
Step 2.3 Set up an S3-compatible object store
You can use AWS S3, MinIO, or other S3-compatible object store.
Please see create an S3 bucket for the example AWS S3 bucket configuration.
Step 2.4 Deploy LLMariner
Run
# Logout of helm registry to perform an unauthenticated pull against the public ECR
helm registry logout public.ecr.aws
helm upgrade --install \
--namespace llmariner \
--create-namespace \
llmariner oci://public.ecr.aws/cloudnatix/llmariner-charts/llmariner \
--values <values.yaml>
Here is an example values.yaml:
tags:
control-plane: false
global:
worker:
controlPlaneAddr: api.llm.cloudnatix.com:443
tls:
enable: true
registrationKeySecret:
name: cluster-registration-key
key: regKey
# Update this to your S3 object store.
objectStore:
s3:
bucket: cloudnatix-installation-demo
endpointUrl: ""
region: us-west-2
# Update this to the k8s secret required to access the S3 object store.
awsSecret:
# Name of the secret.
name: aws
# Secret key for the access key ID.
accessKeyIdKey: accessKeyId
# Secret key for the secret access key.
secretAccessKeyKey: secretAccessKey
inference-manager-engine:
inferenceManagerServerWorkerServiceAddr: inference.llm.cloudnatix.com:443
replicaCount: 2
runtime:
runtimeImages:
ollama: mirror.gcr.io/ollama/ollama:0.6.3-rc0
vllm: mirror.gcr.io/vllm/vllm-openai:v0.8.5
triton: nvcr.io/nvidia/tritonserver:24.09-trtllm-python-py3
engineHeartbeat:
reconnectOnNoHeartbeat: true
heartbeatTimeout: 120s
model:
default:
runtimeName: vllm
overrides:
meta-llama/Llama-3.2-1B-Instruct:
preloaded: false
runtimeName: vllm
resources:
limits:
nvidia.com/gpu: 1
model-manager-loader:
baseModels:
- meta-llama/Llama-3.2-1B-Instruct
downloader:
kind: huggingFace
huggingFace:
cacheDir: /tmp/.cache/huggingface/hub
huggingFaceSecret:
name: huggingface-key
apiKeyKey: apiKey
job-manager-dispatcher:
notebook:
llmarinerBaseUrl: https://api.llm.cloudnatix.com/v1
session-manager-agent:
sessionManagerServerWorkerServiceAddr: session.llm.cloudnatix.com:443
2.2 - Tutorials
Here are the tutorials of LLMariner.
Use OpenAI Python Library
You can download the following Jupyter Notebook and exercise the tutorial:
Fine-tune Models
This section goes through model fine-tuning using Llama3.2-1B-Instruct. We follow the following page and create a model that answers questions in a sarcastic fashion.
You can also check this video to see the overall flow.
Step 1. Download a base model
Change the model-manager-loader config so that Llama3.2-1B-Instruct is downloaded to your S3 bucket.
model-manager-loader:
baseModels:
- meta-llama/Llama-3.2-1B-Instruct
Once the model is loaded, you can see the model name in the output of llma models list.
Step 2. Create a training dataset
Run the following Python script to create a training dataset file.
from datasets import load_dataset
import json
dataset = load_dataset('csv', data_files={
'train': 'https://raw.githubusercontent.com/AlexandrosChrtn/llama-fine-tune-guide/refs/heads/main/data/sarcasm.csv'
})['train']
with open('training.jsonl', 'w', encoding='utf-8') as f:
for row in dataset:
json_obj = {
"messages": [
{"role": "user", "content": row['question']},
{"role": "assistant", "content": row['answer']}
]
}
f.write(json.dumps(json_obj) + '\n')
print("Training data has been saved to training.jsonl")
Verify that the first lines of the file looks like below:
{"messages": [{"role": "user", "content": "Who invented the light bulb?"}, {"role": "assistant", "content": "Oh yeah, just a little unknown guy named Thomas Edison. You might have heard of him... if you pay attention at all."}]}
{"messages": [{"role": "user", "content": "Is the sky blue?"}, {"role": "assistant", "content": "Wow, you're asking that? Next, you'll tell me water is wet."}]}
If you want to validate the training data format, you can use the Python script available from the OpenAI Cookbook.
Step 3. Upload a training dataset
You can either upload the file by the OpenAI Python library or create a “link” with the llma CLI.
If you use the OpenAI Python library, run the following script:
from openai import OpenAI
client = OpenAI(
base_url=os.getenv("LLMARINER_BASE_URL"),
api_key=os.getenv("LLMARINER_API_KEY"),
)
file = client.files.create(
file=open("./training.jsonl", "rb"),
purpose="fine-tune",
)
print("Uploaded file. ID=%s" % file.id)
Environment variable LLMARINER_BASE_URL and LLMARINER_API_KEY must be specified.
You can generate an API key by running llma auth api-keys create.
You can also just create a file object by specifying the location of the S3 object path. For example,
the following command creates a new file object that points to s3://<my-bucket>/training-data/training.jsonl.
aws s3 cp training.jsonl s3://<my-bucket>/training-data/training.jsonl
llma storage files create-link \
--object-path s3://<my-bucket>/training-data/training.jsonl \
--purpose fine-tune
Step 4. Submit a fine-tuning job
Submit a job that fine-tunes Llama3.2-1B-Instruct. You can run the following Python script by passing the file ID as its argument.
import os
import sys
from openai import OpenAI
if len(sys.argv) != 2:
print("Usage: python %s <training_file>" % sys.argv[0])
sys.exit(1)
training_file = sys.argv[1]
client = OpenAI(
base_url=os.getenv("LLMARINER_BASE_URL"),
api_key=os.getenv("LLMARINER_API_KEY"),
)
resp = client.fine_tuning.jobs.create(
model="meta-llama-Llama-3.2-1B-Instruct",
suffix="fine-tuning",
training_file=training_file,
hyperparameters={
"n_epochs": 20,
}
)
print('Created job. ID=%s' % resp.id)
Step 5. Wait for the job completion
You can check the status of the job by running llma fine-tuning jobs get <JOB ID>. You can
also check logs or exec into the container by running llma fine-tuning jobs logs <JOB ID>
or llma fine-tuning jobs exec <JOB ID>.
Step 6. Run chat completion with the generated model.
Once the job completes, you can find the generated model by running llma fine-tuning jobs get <JOB ID> or llma models list.
Then you can use the model with chat completion. Example questions are:
- Who is Edison?
- Why is the sky blue?
3 - Features
LLMariner features
3.1 - Inference with Open Models
Users can run chat completion with open models such as Google Gemma, LLama, Mistral, etc. To run chat completion, users can use the OpenAI Python library,
llma CLI, or API endpoint.Chat Completion
Here is an example chat completion command with the llma CLI.
llma chat completions create --model google-gemma-2b-it-q4_0 --role user --completion "What is k8s?"
If you want to use the Python library, you first need to create an API key:
llma auth api-keys create <key name>
You can then pass the API key to initialize the OpenAI client and run the completion:
from openai import OpenAI
client = OpenAI(
base_url="<Base URL (e.g., http://localhost:8080/v1)>",
api_key="<API key secret>"
)
completion = client.chat.completions.create(
model="google-gemma-2b-it-q4_0",
messages=[
{"role": "user", "content": "What is k8s?"}
],
stream=True
)
for response in completion:
print(response.choices[0].delta.content, end="")
print("\n")
You can also just call client = OpenAI() if you set environment variables OPENAI_BASE_URL and OPENAI_API_KEY.
If you want to hit the API endpoint directly, you can use curl. Here is an example.
curl \
--request POST \
--header "Authorization: Bearer ${LLMARINER_TOKEN}" \
--header "Content-Type: application/json" \
--data '{"model": "google-gemma-2b-it-q4_0", "messages": [{"role": "user", "content": "What is k8s?"}]}' \
http://localhost:8080/v1/chat/completions
Please see the fine-tuning page if you want to generate a fine-tuning model and use that for chat completion.
Tool Calling
vLLM requires additional flags (link to use tool calling.
You can specify the flags with vllmExtraFlags. Here is an example configuration:
inference-manager-engine:
...
model:
overrides:
meta-llama-Meta-Llama-3.3-70B-Instruct-fp8-dynamic:
runtimeName: vllm
resources:
limits:
nvidia.com/gpu: 4
vllmExtraFlags:
- --chat-template
- examples/tool_chat_template_llama3.1_json.jinja
- --enable-auto-tool-choice
- --tool-call-parser
- llama3_json
- --max-model-len
- "8192"
Here is an example curl command:
curl \
--request POST \
--header "Authorization: Bearer ${LLMARINER_TOKEN}" \
--header "Content-Type: application/json" \
--data '{
"model": "meta-llama-Meta-Llama-3.3-70B-Instruct-fp8-dynamic",
"messages": [{"role": "user", "content": "What is the weather like in San Francisco?"}],
"tools": [{
"type": "function",
"function": {
"name": "get_weather",
"description": "Get current weather for a given location.",
"parameters": {
"type": "object",
"properties": {
"location": {
"type": "string",
"description": "City and country"
}
}
},
"strict": true
}
}]
}' http://localhost:8080/v1/chat/completions
The output will have the tool_calls in its message.
{
...
"choices": [
{
"index": 0,
"message": {
"role": "assistant",
"content": null,
"tool_calls": [
{
"id": "chatcmpl-tool-e698e3e36f354d089302b79486e4a702",
"type": "function",
"function": {
"name": "get_weather",
"arguments": "{\"location\": \"San Francisco, USA\"}"
}
}
]
},
"logprobs": null,
"finish_reason": "tool_calls",
"stop_reason": 128008
}
],
...
}
Audio Transcription
LLMariner supports the /v1/audio/transcriptions API. You can use a model like OpenAI/Whispter for this API.
CLI:
llma audio transcriptions create --model openai-whisper-large-v3-turbo --file <audio file>
Python:
from openai import OpenAI
client = OpenAI(
base_url="<Base URL (e.g., http://localhost:8080/v1)>",
api_key="<API key secret>"
)
response = client.audio.transcriptions.create(
model="openai-whisper-large-v3-turbo",
file=open("<audio file>", "rb")
)
print(response)
curl:
curl \
--request POST \
--header "Authorization: Bearer ${LLMARINER_TOKEN}" \
--header "Content-Type: multipart/form-data" \
-F model=openai-whisper-large-v3-turbo \
-F file="@<audio file>" \
http://localhost:8080/v1/audio/transcriptions
Model Response API
LLMariner supports the /v1/responses API. You can, for example, use openai/gpt-oss-120b for this API.
curl \
--request POST \
--header "Authorization: Bearer ${LLMARINER_TOKEN}" \
--header 'Content-Type: application/json' \
--data '{
"model": "openai-gpt-oss-120b",
"input": "What is the capital of France?",
"tools": [{
"type": "function",
"name": "get_weather",
"description": "Get current temperature for a given location.",
"parameters": {
"type": "object",
"properties": {
"location": {
"type": "string",
"description": "City and country e.g. Bogotá, Colombia"
}
},
"required": [
"location"
],
"additionalProperties": false
}
}],
"tool_choice": "auto"
}' \
http://localhost:8080/v1/responses
Model Runtime Configuration
We currently support vLLM, Ollama, and Nvidia Triton Inference Server
as an inference runtime. You can change a runtime for each model. For
example, in the following configuration, the default runtime is set to
vLLM, and Ollama is used for deepseek-r1:1.5b.
inference-manager-engine:
...
model:
default:
runtimeName: vllm # Default runtime
resources:
limits:
nvidia.com/gpu: 1
overrides:
lmstudio-community/phi-4-GGUF/phi-4-Q6_K.gguf:
preloaded: true
vllmExtraFlags:
- --tokenizer
- microsoft/phi-4
deepseek-r1:1.5b:
runtimeName: ollama # Override the default runtime
preloaded: true
resources:
limits:
nvidia.com/gpu: 0
By default, one Pod serves only one pod. If you want to make one Ollama pod serve multiple models, you can set dynamicModelLoading to true.
inference-manager-engine:
ollama:
dynamicModelLoading: true
3.2 - Model Loading
The following shows how to load models in LLMariner.
Overview
LLMariner hosts LLMs in a Kubernetes cluster by downloading models from source repos and uploading to an S3-compatible object store. The supported source model repositories are following:
- LLMariner official model repository
- Hugging Face repositories
- Ollama repositories
- S3 bucket
If you already know models that you would like to download, you can specify them
in values.yaml. Here is an example configuration where two models are downloaded from
the LLMariner official model repository.
model-manager-loader:
baseModels:
- google/gemma-2b-it-q4_0
- sentence-transformers/all-MiniLM-L6-v2-f16
You can always update values.yaml and upgrade the Helm chart to download additional models.
You can also run llma models (base|fine-tuned) create to download additional models. For example, the following command
will download deepseek-r1:1.5b from the Ollama repository.
llma models create base deepseek-r1:1.5b --source-repository ollama
You can check the status of the download with:
llma models list
Once the download has been completed, you can activate the model. The activated model becomes ready
for inference once inference-manager-engine loads the model.
Note
To download models from Hugging Face, you need additional configuration to embed the Hugging Face API key tomodel-manager-loader. Please see the page below for details.Model Configuration
There are two ways to configure model deployment: Helm chart and model API.
In the Helm chart, you can put your own configuration under inference-manager-engine.model and
control GPU allocation, extra flags to runtime, number of replicas, etc. Here is an example:
inference-manager-engine:
model:
default:
runtimeName: vllm
replicas: 1
resources:
limits:
nvidia.com/gpu: 1
overrides:
meta-llama/Llama-3.2-1B-Instruct:
vllmExtraFlags:
- --enable-lora
- --max-lora-rank
- "64"
openai/gpt-oss-120b:
image: vllm/vllm-openai:gptoss
replicas: 2
Please see https://artifacthub.io/packages/helm/inference-manager-engine/inference-manager-engine?modal=values for details.
To use the model API to configure model deployment, you first
need to set inference-manager-engine.model.enableOverrideWithModelConfig to true.
Then you can specify the deployment configuration when running llma models (base|fine-tuned) create or llma models update. For example,
the following command will deploy four replicas of an inference
runtime to serve deepseek-r1:1.5b. Two GPUs are allocated to each
replica.
llma models create base deepseek-r1:1.5b \
--source-repository ollama \
--replicas 4 \
--gpu 2
Official Model Repository
This is the default configuration. The following is a list of supported models where we have validated.
| Model | Quantizations | Supporting runtimes |
|---|---|---|
| TinyLlama/TinyLlama-1.1B-Chat-v1.0 | None | vLLM |
| TinyLlama/TinyLlama-1.1B-Chat-v1.0 | AWQ | vLLM |
| deepseek-ai/DeepSeek-Coder-V2-Lite-Base | Q2_K, Q3_K_M, Q3_K_S, Q4_0 | Ollama |
| deepseek-ai/DeepSeek-Coder-V2-Lite-Instruct | Q2_K, Q3_K_M, Q3_K_S, Q4_0 | Ollama |
| deepseek-ai/deepseek-coder-6.7b-base | None | vLLM, Ollama |
| deepseek-ai/deepseek-coder-6.7b-base | AWQ | vLLM |
| deepseek-ai/deepseek-coder-6.7b-base | Q4_0 | vLLM, Ollama |
| fixie-ai/ultravox-v0_3 | None | vLLM |
| google/gemma-2b-it | None | Ollama |
| google/gemma-2b-it | Q4_0 | Ollama |
| intfloat/e5-mistral-7b-instruct | None | vLLM |
| meta-llama/Llama-3.2-1B-Instruct | None | vLLM |
| meta-llama/Meta-Llama-3.3-70B-Instruct | AWQ, FP8-Dynamic | vLLM |
| meta-llama/Meta-Llama-3.1-70B-Instruct | AWQ | vLLM |
| meta-llama/Meta-Llama-3.1-70B-Instruct | Q2_K, Q3_K_M, Q3_K_S, Q4_0 | vLLM, Ollama |
| meta-llama/Meta-Llama-3.1-8B-Instruct | None | vLLM |
| meta-llama/Meta-Llama-3.1-8B-Instruct | AWQ | vLLM, Triton |
| meta-llama/Meta-Llama-3.1-8B-Instruct | Q4_0 | vLLM, Ollama |
| nvidia/Llama-3.1-Nemotron-70B-Instruct | Q2_K, Q3_K_M, Q3_K_S, Q4_0 | vLLM |
| nvidia/Llama-3.1-Nemotron-70B-Instruct | FP8-Dynamic | vLLM |
| mistralai/Mistral-7B-Instruct-v0.2 | Q4_0 | Ollama |
| sentence-transformers/all-MiniLM-L6-v2-f16 | None | Ollama |
Please note that some models work only with specific inference runtimes.
Hugging Face Repositories
First, create a k8s secret that contains the Hugging Face API key.
kubectl create secret generic \
huggingface-key \
-n llmariner \
--from-literal=apiKey=${HUGGING_FACE_HUB_TOKEN}
The above command assumes that LLMarine runs in the llmariner namespace.
Then deploy LLMariner with the following values.yaml.
model-manager-loader:
downloader:
kind: huggingFace
huggingFace:
cacheDir: /tmp/.cache
huggingFaceSecret:
name: huggingface-key
apiKeyKey: apiKey
baseModels:
- Qwen/Qwen2-7B
- TheBloke/TinyLlama-1.1B-Chat-v1.0-AWQ
Then the model should be loaded by model-manager-loader. Once the loading completes, the model name
should show up in the output of llma models list.
When you use a GGUF model with vLLM, please specify --tokenizer=<original model> in vllmExtraFlags. Here is an example
configuration for Phi 4.
inference-manager-engine:
...
model:
default:
runtimeName: vllm
overrides:
lmstudio-community/phi-4-GGUF/phi-4-Q6_K.gguf:
preloaded: true
resources:
limits:
nvidia.com/gpu: 1
vllmExtraFlags:
- --tokenizer
- microsoft/phi-4
Ollama Repositories
You can configure Ollama as model source repos by setting model-manager-loader.downloader.kind to ollama. The following is an example values.yaml that downloads deepseek-r1:1.5b from Ollama.
model-manager-loader:
downloader:
kind: ollama
baseModels:
- deepseek-r1:1.5b
S3 Bucket
If you want to download models from your S3 bucket, you can specify the bucket configuration under
model-manager-loader.downloader.s3. For example, if you store model files under s3://my-models/v1/base-models/<model-name>,
you can specify the downloader config as follows:
model-manager-loader:
downloader:
kind: s3
s3:
# The s3 endpoint URL.
endpointUrl: https://s3.us-west-2.amazonaws.com
# The region name where the models are stored.
region: us-west-2
# The bucket name where the models are stored.
bucket: my-models
# The path prefix of the model.
pathPrefix: v1/base-models
# Set to true if the bucket is public and we don't want to
# use the credential attached to the pod.
isPublic: false
3.3 - Retrieval-Augmented Generation (RAG)
This page describes how to use RAG with LLMariner.
Embedding API
If you want to just generate embeddings, you can use the Embedding API, which is compatible with the OpenAI API.
Here are examples:
llma embeddings create --model intfloat-e5-mistral-7b-instruct --input "sample text"
curl \
--request POST \
--header "Authorization: Bearer ${LLMARINER_TOKEN}" \
--header "Content-Type: application/json" \
--data '{
"model": "sentence-transformers-all-MiniLM-L6-v2-f16",
"input": "sample text"
}' \
http://localhost:8080/v1/embeddings
Vector Store API
The first step is to create a vector store and create files in the vector store. Here is an example script with the OpenAI Python library:
from openai import OpenAI
client = OpenAI(
base_url="<LLMariner Endpoint URL>",
api_key="<LLMariner API key>"
)
filename = "llmariner_overview.txt"
with open(filename, "w") as fp:
fp.write("LLMariner builds a software stack that provides LLM as a service. It provides the OpenAI-compatible API.")
file = client.files.create(
file=open(filename, "rb"),
purpose="assistants",
)
print("Uploaded file. ID=%s" % file.id)
vs = client.beta.vector_stores.create(
name='Test vector store',
)
print("Created vector store. ID=%s" % vs.id)
vfs = client.beta.vector_stores.files.create(
vector_store_id=vs.id,
file_id=file.id,
)
print("Created vector store file. ID=%s" % vfs.id)
Once the files are added into vector store, you can run the completion request with the RAG model.
from openai import OpenAI
client = OpenAI(
base_url="<Base URL (e.g., http://localhost:8080/v1)>",
api_key="<API key secret>"
)
completion = client.chat.completions.create(
model="google-gemma-2b-it-q4_0",
messages=[
{"role": "user", "content": "What is LLMariner?"}
],
tool_choice = {
"choice": "auto",
"type": "function",
"function": {
"name": "rag"
}
},
tools = [
{
"type": "function",
"function": {
"name": "rag",
"parameters": {
"vector_store_name": "Test vector store"
}
}
}
],
stream=True
)
for response in completion:
print(response.choices[0].delta.content, end="")
print("\n")
If you want to hit the API endpoint directly, you can use curl. Here is an example.
curl \
--request POST \
--header "Authorization: Bearer ${LLMARINER_TOKEN}" \
--header "Content-Type: application/json" \
--data '{
"model": "google-gemma-2b-it-q4_0",
"messages": [{"role": "user", "content": "What is LLMariner?"}],
"tool_choice": {
"choice": "auto",
"type": "function",
"function": {
"name": "rag"
}
},
"tools": [{
"type": "function",
"function": {
"name": "rag",
"parameters": "{\"vector_store_name\":\"Test vector store\"}"
}
}]}' \
http://localhost:8080/v1/chat/completions
3.4 - Model Fine-tuning
This page describes how to fine-tune models with LLMariner.
Submitting a Fine-Tuning Job
You can use the OpenAI Python library to submit a fine-tuning job. Here is an example snippet that uploads a training file and uses that to run a fine-tuning job.
from openai import OpenAI
client = OpenAI(
base_url="<LLMariner Endpoint URL>",
api_key="<LLMariner API key>"
)
file = client.files.create(
file=open(training_filename, "rb"),
purpose="fine-tune",
)
job = client.fine_tuning.jobs.create(
model="google-gemma-2b-it",
suffix="fine-tuning",
training_file=file.id,
)
print('Created job. ID=%s' % job.id)
Once a fine-tuning job is submitted, a k8s Job is created. A Job runs in a namespace where a user's project is associated.
You can check the status of the job with the Python script or the llma CLI.
print(client.fine_tuning.jobs.list())
llma fine-tuning jobs list
llma fine-tuning jobs get <job-id>
Once the job completes, you can check the generated models.
fine_tuned_model = client.fine_tuning.jobs.list().data[0].fine_tuned_model
print(fine_tuned_model)
Then you can get the model ID and use that for the chat completion request.
completion = client.chat.completions.create(
model=fine_tuned_model,
...
Create File Objects without Uploading
You can also create file objects without uploading. The following command creates a file for a specified S3 object.
llma storage files create-link --object-path models/my-model --purpose fine-tune
This option is useful when the S3 bucket is not accessible from the LLMariner control-plane component.
Note
Please note that specified file objects will be accessible from fine-tuning jobs. You should not create a file of an S3 object if the object should not be visible to users who can submit fine-tuning jobs.Debugging a Fine-Tuning Job
You can use the llma CLI to check the logs and exec into the pod.
llma fine-tuning jobs logs <job-id>
llma fine-tuning jobs exec <job-id>
Changing the Number of GPUs allocated to Jobs
By default one GPU is allocated to each fine-tuning job. If you want to change the number
of GPUs allocated to jobs, please change the value of job-manager-dispatcher.job.numGpus in Helm values.
For example, the following will allocate 4 GPUs to each fine-tuning job.
job-manager-dispatcher:
job:
numGpus: 4
Managing Quota
LLMariner allows users to manage GPU quotas with integration with Kueue.
You can install Kueue with the following command:
export VERSION=v0.6.2
kubectl apply -f https://github.com/kubernetes-sigs/kueue/releases/download/$VERSION/manifests.yaml
Once the install completes, you should see kueue-controller-manager in the kueue-system namespace.
$ kubectl get po -n kueue-system
NAME READY STATUS RESTARTS AGE
kueue-controller-manager-568995d897-bzxg6 2/2 Running 0 161m
You can then define ResourceFlavor, ClusterQueue, and LocalQueue to manage quota. For example, when you want to allocate 10 GPUs to team-a whose project namespace is team-a-ns, you can define ClusterQueue and LocalQueue as follows:
apiVersion: kueue.x-k8s.io/v1beta1
kind: ClusterQueue
metadata:
name: team-a
spec:
namespaceSelector: {} # match all.
cohort: org-x
resourceGroups:
- coveredResources: [gpu]
flavors:
- name: gpu-flavor
resources:
- name: gpu
nominalQuota: 10
---
apiVersion: kueue.x-k8s.io/v1beta1
kind: LocalQueue
metadata:
namespace: team-a-ns
name: team-a-queue
spec:
clusterQueue: team-a
Enabling Dynamic LoRA loading
By default, an inference runtime pod is created for each fine-tuned model. If you want to load LoRA on a pod that serves a base model, enable dynamic LoRA loading.
You need to set inference-manager-engine.vllm.dynamicLoRALoading to true and add --enable-lora to vllmExtraFlags of the base model.
Here is an example configuration.
inference-manager-engine:
vllm:
dynamicLoRALoading: true
model:
default:
...
overrides:
Qwen/Qwen3-1.7B:
vllmExtraFlags:
- --enable-lora
- --max-lora-rank
- "64"
3.5 - General-purpose Training
LLMariner allows users to run general-purpose training jobs in their Kubernetes clusters.
Creating a Training Job
You can create a training job from the local pytorch code by running the following command.
llma batch jobs create \
--image="pytorch-2.1" \
--from-file=my-pytorch-script.py \
--from-file=requirements.txt \
--file-id=<file-id> \
--command "python -u /scripts/my-pytorch-script.py"
Once a training job is created, a k8s Job is created. The job runs the command specified in the --command flag, and files specified in the --from-file flag are mounted to the /scripts directory in the container. If you specify the --file-id flag (optional), the file will be download to the /data directory in the container.
You can check the status of the job by running the following command.
llma batch jobs list
llma batch jobs get <job-id>
Debugging a Training Job
You can use the llma CLI to check the logs of a training job.
llma batch jobs logs <job-id>
PyTorch Distributed Data Parallel
LLMariner supports PyTorch Distributed Data Parallel (DDP) training. You can run a DDP training job by specifying the number of per-node GPUs and the number of workers in the --gpu and --workers flags, respectively.
llma batch jobs create \
--image="pytorch-2.1" \
--from-file=my-pytorch-ddp-script.py \
--gpu=1 \
--workers=3 \
--command "python -u /scripts/my-pytorch-ddp-script.py"
Created training job is pre-configured some DDP environment variables; MASTER_ADDR, MASTER_PORT, WORLD_SIZE, and RANK.
3.6 - Jupyter Notebook
LLMariner allows users to run a Jupyter Notebook in a Kubernetes cluster. This functionality is useful when users want to run ad-hoc Python scripts that require GPU.
Creating a Jupyter Notebook
To create a Jupyter Notebook, run:
llma workspace notebooks create my-notebook
By default, there is no GPU allocated to the Jupyter Notebook. If you want to allocate a GPU to the Jupyter Notebook, run:
llma workspace notebooks create my-gpu-notebook --gpu 1
There are other options that you can specify when creating a Jupyter Notebook, such as environment. You can see the list of options by using the --help flag.
Once the Jupyter Notebook is created, you can access it by running:
# Open the Jupyter Notebook in your browser
llma workspace notebooks open my-notebook
Stopping and Restarting a Jupyter Notebook
To stop a Jupyter Notebook, run:
llma workspace notebooks stop my-notebook
To restart a Jupyter Notebook, run:
llma workspace notebooks start my-notebook
You can check the current status of the Jupyter Notebook by running:
llma workspace notebooks list
llma workspace notebooks get my-notebook
OpenAI API Integration
Jupyter Notebook can be integrated with OpenAI API. Created Jupyter Notebook is pre-configured with OpenAI API URL and API key. All you need to do is to install the openai package.
To install openai package, run the following command in the Jupyter Notebook terminal:
pip install openai
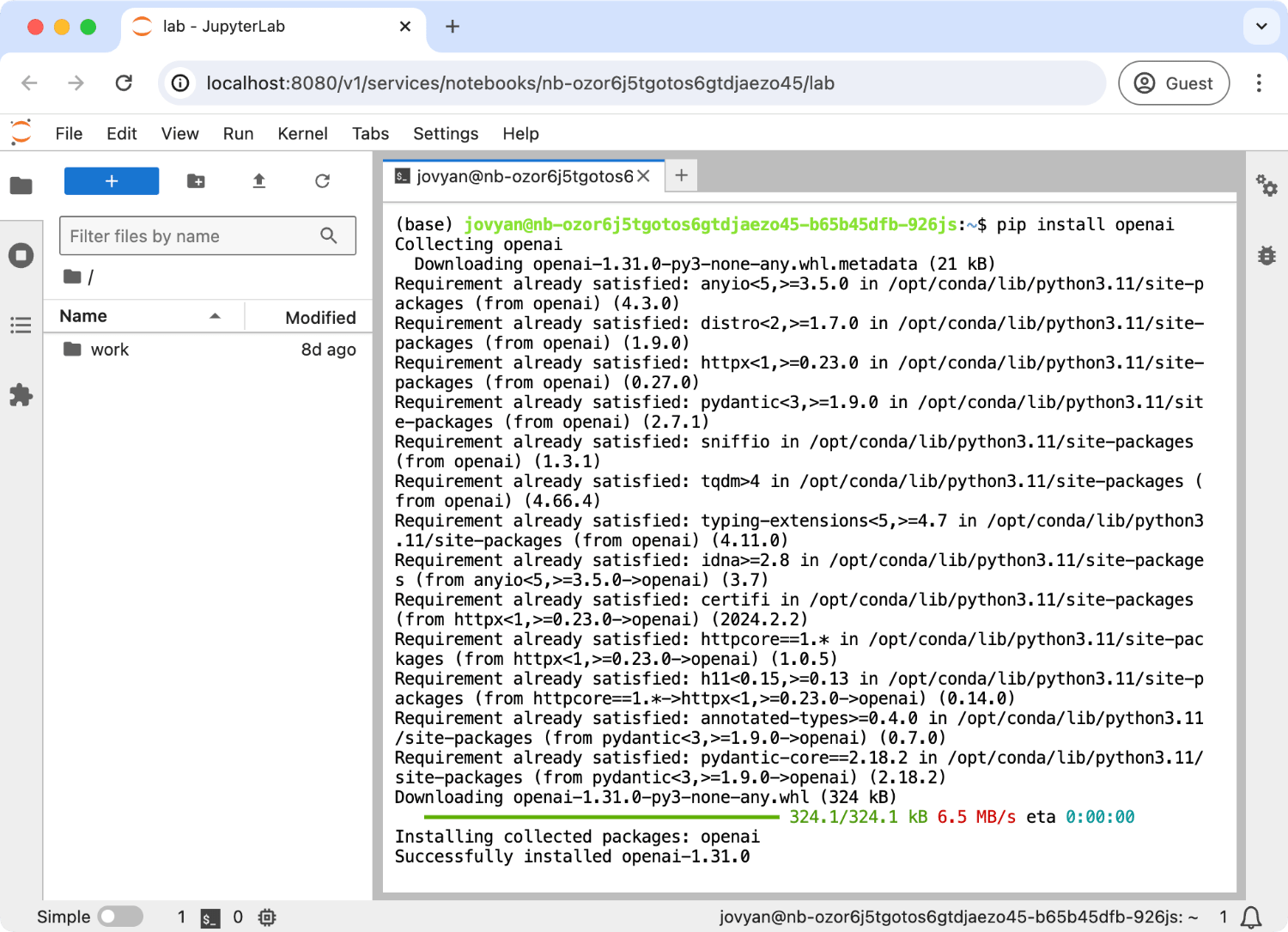
Now, you can use the OpenAI API in the Jupyter Notebook. Here is an example of using OpenAI API in the Jupyter Notebook:
from openai import OpenAI
client = OpenAI()
completion = client.chat.completions.create(
model="google-gemma-2b-it-q4_0",
messages=[
{"role": "user", "content": "What is k8s?"}
],
stream=True
)
for response in completion:
print(response.choices[0].delta.content, end="")
print("\n")
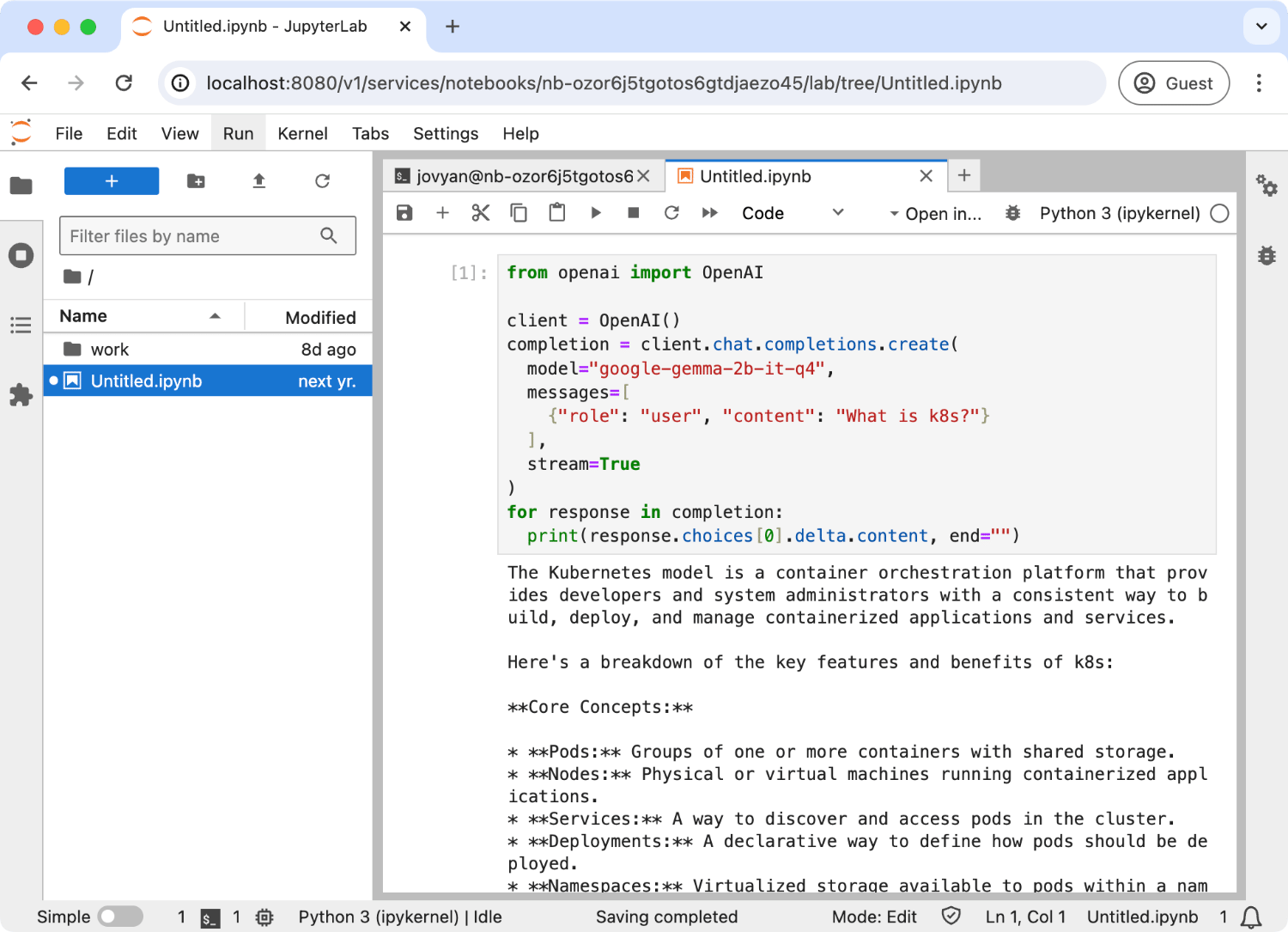
Note
By default, pre-configured API key is a JWT and it can expire. You can also pass your API key to theOpenAI client.Running vLLM inside the Jupyter Notebook
You can run a vLLM server inside a Jupyter Notebook and access it from your local desktop/laptop.
First, create a Notebook with --gpu and --port. --gpu will allocate a GPU to the Notebook pod, and --port will expose a specified port externally. For example, the following command will create a Notebook with one GPU and expose port 8000.
llma workspace notebooks create my-notebook --gpu 1 --port 8000
Once the Notebook starts running, access it.
llma workspace notebooks open my-notebook
Then go to the terminal and run:
pip install vllm
# To resolve the vLLM dependency issue.
pip install "numpy<2"
# You can choose other model. Set env var HUGGING_FACE_HUB_TOKEN if needed.
vllm serve TinyLlama/TinyLlama-1.1B-Chat-v1.0
This will start a vLLM server at port 8000.
You can obtain the base URL of the vLLM server with the following command:
llma workspace notebooks open my-notebook --port 8000 --no-open
You need to set the Authorization header of requests to an LLMariner API key. Here is an example to list model and send a chat completion request.
LLMARINER_BASE_URL=$(llma workspace notebooks open vllm-test --port 8000 --no-open | grep http)
# Create a new API key and save its secret
LLMARINER_TOKEN=$(llma auth api-keys create test-key | sed -n 's/.*Secret: \(.*\)/\1/p')
# List models.
curl \
--header "Authorization: Bearer ${LLMARINER_TOKEN}" \
--header "Content-Type: application/json" \
"${LLMARINER_BASE_URL}/v1/models" | jq .
# Send a chat completion request.
curl \
--request POST \
--header "Authorization: Bearer ${LLMARINER_TOKEN}" \
--header "Content-Type: application/json" \
--data '{"model": "TinyLlama/TinyLlama-1.1B-Chat-v1.0", "messages": [{"role": "user", "content": "What is k8s?"}]}' \
"${LLMARINER_BASE_URL}/v1/chat/completions" | jq .
3.7 - API and GPU Usage Optimization
Note
Work-in-progress.API Usage Visibility
Inference Request Rate-limiting
Optimize GPU Utilization
Auto-scaling of Inference Runtimes
Scheduled Scale Up and Down of Inference Runtimes
If you want to scale up/down model runtimes based on certain schedules, you can enable the scheduled shutdown feature.
Here is an example values.yaml.
inference-manager-engine:
runtime:
scheduledShutdown:
enable: true
schedule:
# Pods are up between 9AM to 5PM.
scaleUp: "0 9 * * *"
scaleDown: "0 17 * * *"
timeZone: "Asia/Tokyo"
3.8 - GPU Federation
Users can create a global pool of GPUs across multiple clusters and efficiently utilize them.
Overview
LLMariner GPU federation creates a global pool of GPUs across multiple clusters so that end users can submit training jobs without knowing GPU availability of individual K8s clusters.
End users can continue to use their existing tools to interact with
the global GPU pool. For example, a user can create a new job with
kubectl create. LLMariner schedules it one of the worker clusters
where a sufficient number of GPUs are available, and pods will start
running there.
Please see this demo video for an example job submissions flow.
Install Procedure
Prerequisites
The following K8s clusters are required:
- A k8s cluster for running the LLMariner control plane
- Worker k8s clusters with GPU nodes
- A k8s cluster that works as an aggregation point for the worker clusters (Hereafter we call this proxy cluster)
The proxy cluster does not require GPU nodes.
Step 1. Install the LLMariner control plane and worker plane
Follow multi_cluster_deployment and install the LLMariner control plane and worker plane.
Step 2. Create a service account API key and a k8s secret
Run the following command to create an API key for the service account.
llma auth api-keys create key-for-proxy-cluster --service-account --role tenant-system
We use this API key in the proxy cluster. Run the following command to create a K8s secret in the proxy cluster.
kubectl create namesapce llmariner
kubectl create secret -n llmariner generic syncer-api-key --from-literal=key=<API key secret>
Step 3. Install job-manager-syncer in the proxy cluster
Run:
helm upgrade \
--install \
-n llmariner \
llmariner \
oci://public.ecr.aws/cloudnatix/llmariner-charts/llmariner \
-f ./values.yaml
Here is the example values.yaml.
tags:
# Set these to only deploy job-manager-syncer
control-plane: false
worker: false
tenant-control-plane: true
job-manager-syncer:
# The gRPC endpoint of LLMariner control plane (same value as `global.worker.controlPlaneAddr` in the worker plane config).
jobManagerServerSyncerServiceAddr: control-plane:80
# The base URL of the LLMariner API endpoint.
sessionManagerEndpoint: http://control-plane/v1
tenant:
# k8s secret name and key that contains the LLMariner API key secret.
apiKeySecret:
name: syncer-api-key
key: key
Step 4. Submit a test job to the proxy cluster
Use kubectl or other command and submit a test job requesting GPU to the proxy cluster. The submitted job will be redirected to
one of the worker clusters that have been registered.
3.9 - User Management
Describes the way to manage users
LLMariner installs Dex by default. Dex is an identity service that uses OpenID Connect for authentication.
The Helm chart for Dex is located at https://github.com/llmariner/rbac-manager/tree/main/deployments/dex-server. It uses a built-in local connector and has the following configuration by default:
staticPasswords:
- userID: 08a8684b-db88-4b73-90a9-3cd1661f5466
username: admin
email: admin@example.com
# bcrypt hash of the string: $(echo password | htpasswd -BinC 10 admin | cut -d: -f2)
hash: "$2a$10$2b2cU8CPhOTaGrs1HRQuAueS7JTT5ZHsHSzYiFPm1leZck7Mc8T4W"
You can switch a connector to an IdP in your environment (e.g., LDAP, GitHub). Here is an example connector configuration with Okta:
global:
auth:
oidcIssuerUrl: https://<LLMariner endpoint URL>/v1/dex
dex-server:
oauth2:
passwordConnector:
enable: false
responseTypes:
- code
connectors:
- type: oidc
id: okta
name: okta
config:
issuer: <Okta issuer URL>
clientID: <Client ID of an Okta application>
clientSecret: <Client secret of an Okta application>
redirectURI: https://<LLMariner endpoint URL>/v1/dex/callback
insecureSkipEmailVerified: true
enablePasswordDb: false
staticPassword:
enable: false
Please refer to the Dex documentations for more details.
The Helm chart for Dex creates an ingress so that HTTP requests to v1/dex are routed to Dex. This endpoint URL works as the OIDC issuer URL that CLI and backend servers use.
3.10 - Access Control with Organizations and Projects
The way to configure access control using organizations and projects
Overview
Basic Concepts
LLMariner provides access control with two concepts: Organizations and Projects. The basic concept follows OpenAI API.
You can define one or more than one organization. In each organization, you can define one or more than one project. For example, you can create an organization for each team in your company, and each team can create individual projects based on their needs.
A project controls the visibility of resources such as models, fine-tuning jobs. For example, a model that is generated by a fine-tuned job in project P is only visible from project members in P.
A project is also associated with a Kubernetes namespace. Fine-tuning jobs for project P run in the Kubernetes namespace associated with P (and quota management is applied).
Roles
Each user has an organization role and a project role, and these roles control resources that a user can access and actions that a user can take.
An organization role is either owner or reader. A project role is either owner or member. If you want to allow a user to use LLMariner without any organization/project management privilege, you can grant the organization role reader and the project role member. If you want to allow a user to manage the project, you can grant the project role owner.
Here is an diagram shows an example role assignment.
The following summarizes how these role implements the access control:
- A user can access resources in project
Pin organizationOif the user is amemberofP,ownerofP, orownerofO. - A user can manage project
P(e.g., add a new member) in organizationOif the user is anownerofPorownerofO. - A user can manage organization
O(e.g., add a new member) if the user is anownerofO. - A user can create a new organization if the user is an
ownerof the initial organization that is created by default.
Please note that a user who has the reader organization role cannot access resources in the organization unless the user is added to a project in the organization.
Creating Organizations and Projects
You can use CLI llma to create a new organization and a project.
Creating a new Organization
You can run the following command to create a new organization.
llma admin organizations create <organization title>
Note
You can also typellm auth orgs instead of llm auth organizations.You can confirm that the new organization is created by running:
llma admin organizations list
Then you can add a user member to the organization.
llma admin organizations add-member <organization title> --email <email-address of the member> --role <role>
The role can be either owner or reader.
You can confirm organization members by running:
llma admin organizations list-members <organization title>
Creating a new Project
You can take a similar flow to create a new project. To create a new project, run:
llma admin projects create --title <project title> --organization-title <organization title>
To confirm the project is created, run:
llma admin projects list
Then you can add a user member to the project.
llma admin projects add-member <project title> --email <email-address of the member> --role <role>
The role can be either owner or member.
You can confirm project members by running:
llma admin projects list-members --title <project title> --organization-title <organization title>
If you want to manage a project in a different organization, you can pass --organization-title <title> in each command. Otherwise, the organization in the current context is used. You can also change the current context by running:
llma context set
Choosing an Organization and a Project
You can use llma context set to set the current context.
llma context set
Then the selected context is applied to CLI commands (e.g., llma models list).
When you create a new API key, the key will be associated with the project in the current context. Suppose that a user runs the following commands:
llma context set # Choose project my-project
llma auth api-keys create my-key
The newly created API key is associated with project my-project.
4 - Integration
Integrate with other projects
4.1 - Open WebUI
Integrate with Open WebUI and get the web UI for the AI assistant.
Open WebUI provides a web UI that works with OpenAI-compatible APIs. You can run Openn WebUI locally or run in a Kubernetes cluster.
Here is an instruction for running Open WebUI in a Kubernetes cluster.
OPENAI_API_KEY=<LLMariner API key>
OPEN_API_BASE_URL=<LLMariner API endpoint>
kubectl create namespace open-webui
kubectl create secret generic -n open-webui llmariner-api-key --from-literal=key=${OPENAI_API_KEY}
kubectl apply -f - <<EOF
apiVersion: apps/v1
kind: Deployment
metadata:
name: open-webui
namespace: open-webui
spec:
selector:
matchLabels:
name: open-webui
template:
metadata:
labels:
name: open-webui
spec:
containers:
- name: open-webui
image: ghcr.io/open-webui/open-webui:main
ports:
- name: http
containerPort: 8080
protocol: TCP
env:
- name: OPENAI_API_BASE_URLS
value: ${OPEN_API_BASE_URL}
- name: WEBUI_AUTH
value: "false"
- name: OPENAI_API_KEYS
valueFrom:
secretKeyRef:
name: llmariner-api-key
key: key
---
apiVersion: v1
kind: Service
metadata:
name: open-webui
namespace: open-webui
spec:
type: ClusterIP
selector:
name: open-webui
ports:
- port: 8080
name: http
targetPort: http
protocol: TCP
EOF
You can then access Open WebUI with port forwarding:
kubectl port-forward -n open-webui service/open-webui 8080
4.2 - Continue
Integrate with Continue and provide an open source AI code assistant.
Continue provides an open source AI code assistant. You can use LLMariner as a backend endpoint for Continue.
As LLMariner provides the OpenAI compatible API, you can set the provider to "openai". apiKey is set to an API key generated by LLMariner, and apiBase is set to the endpoint URL of LLMariner (e.g., http://localhost:8080/v1).
Here is an example configuration that you can put at ~/.continue/config.json.
{
"models": [
{
"title": "Meta-Llama-3.1-8B-Instruct-q4",
"provider": "openai",
"model": "meta-llama-Meta-Llama-3.1-8B-Instruct-q4",
"apiKey": "<LLMariner API key>",
"apiBase": "<LLMariner endpoint>"
}
],
"tabAutocompleteModel": {
"title": "Auto complete",
"provider": "openai",
"model": "deepseek-ai-deepseek-coder-6.7b-base-q4",
"apiKey": "<LLMariner API key>",
"apiBase": "<LLMariner endpoint>",
"completionOptions": {
"presencePenalty": 1.1,
"frequencyPenalty": 1.1
},
},
"allowAnonymousTelemetry": false
}
The following is a demo video that shows the Continue integration that enables the coding assistant with Llama-3.1-Nemotron-70B-Instruct.
4.3 - Aider
Integrate with Aider for AI pair programming
Aider is AI pair programming in your terminal or browser.
Aider supports the OpenAI compatible API, and you can configure the endpoint and the API key with environment variables.
Here is an example installation and configuration procedure.
python -m pip install -U aider-chat
export OPENAI_API_BASE=<Base URL (e.g., http://localhost:8080/v1)>
export OPENAI_API_KEY=<API key>
You can then run Aider in your terminal or browser. Here is an example command that launches Aider in your browser with Llama 3.1 70B.
<Move to your github repo directory>
aider --model openai/meta-llama-Meta-Llama-3.1-70B-Instruct-awq --browser
Please note that the model name requires the openai/ prefix.
https://aider.chat/examples/README.html has example chat transcripts for building applications (e.g., “make a flask app with a /hello endpoint that returns hello world”).
4.4 - AI Shell
Integrate with AI Shell to power your shell with the AI assistant.
AI Shell is an open source tool that converts natural language to shell commands.
npm install -g @builder.io/ai-shell
ai config set OPENAI_API_ENDPOINT=<Base URL (e.g., http://localhost:8080/v1)>
ai config set OPENAI_KEY=<API key>
ai config set MODEL=<model name>
Then you can run the ai command and ask what you want in plain English and generate a shell command with a human readable explanation of it.
ai what is my ip address
4.5 - k8sgpt
Integrate with k8sgpt to diagnose and triage issues in your Kubernetes clusters.
k8sgpt is a tool for scanning your Kubernetes clusters, diagnosing, and triaging issues in simple English.
You can use LLMariner as a backend of k8sgpt by running the following command:
k8sgpt auth add \
--backend openai \
--baseurl <LLMariner base URL (e.g., http://localhost:8080/v1/) \
--password <LLMariner API Key> \
--model <Model ID>
Then you can a command like k8sgpt analyze to inspect your Kubernetes cluster.
k8sgpt analyze --explain
4.6 - Dify
Integrate with Dify for LLM application development.
Dify is is an open-source LLM app development platform. It can orchestrate LLM apps from agents to complex AI workflows, with an RAG engine.
You can add LLMariner as one of Dify’s model providers with the following steps:
- Click the user profile icon.
- Click “Settings”
- Click “Model Provider”
- Search “OpenAI-API-compatible” and click “Add model”
- Configure a model name, API key,a nd API endpoint URL.
You can then use the registered model from your LLM applications. For example, you can create a new application by “Create from Template” and replace the use of an OpenAI model with the configured model.
If you want to deploy Dify in your Kubernetes clusters, follow README.md in the Dify GitHub repository.
4.7 - n8n
Integrate with n8n and get the web UI for the AI assistant.
n8n is a no-code platform for workload automation. You can deploy n8n to your Kubernetes clusters. Here is an example command:
kubectl apply -f - <<EOF
apiVersion: apps/v1
kind: Deployment
metadata:
name: n8n
namespace: n8n
spec:
selector:
matchLabels:
name: n8n
template:
metadata:
labels:
name: n8n
spec:
containers:
- name: n8n
image: docker.n8n.io/n8nio/n8n
ports:
- name: http
containerPort: 5678
protocol: TCP
---
apiVersion: v1
kind: Service
metadata:
name: n8n
namespace: n8n
spec:
type: ClusterIP
selector:
name: n8n
ports:
- port: 5678
name: http
targetPort: http
protocol: TCP
EOF
You can then access n8n with port forwarding:
kubectl port-forward -n n8n service/n8n 5678
You can create an “OpenAI Model” node and configure its base URL and credential to hit LLMariner.
If you are using vLLM as a inference runtime, you will need to enable tool calling. Please see Tool calling for details.
4.8 - Slackbot
Build a Slackbot that integrates with LLMariner
You can build a Slackbot that is integrated with LLMariner. The bot can provide a chat UI with Slack and answer questions from end users.
An example implementation can be found in https://github.com/llmariner/slackbot. You can deploy it in your Kubernetes clusters and build a Slack app with the following configuration:
- Create an app-level token whose scope is
connections:write. - Enable the socket mode. Enable event subscription with the
app_mentions:readscope. - Add the following scopes in “OAuth & Permissions”:
app_mentions:read,chat:write,chat:write.customize, andlinks:write
You can install the Slack application to your workspace and interact.
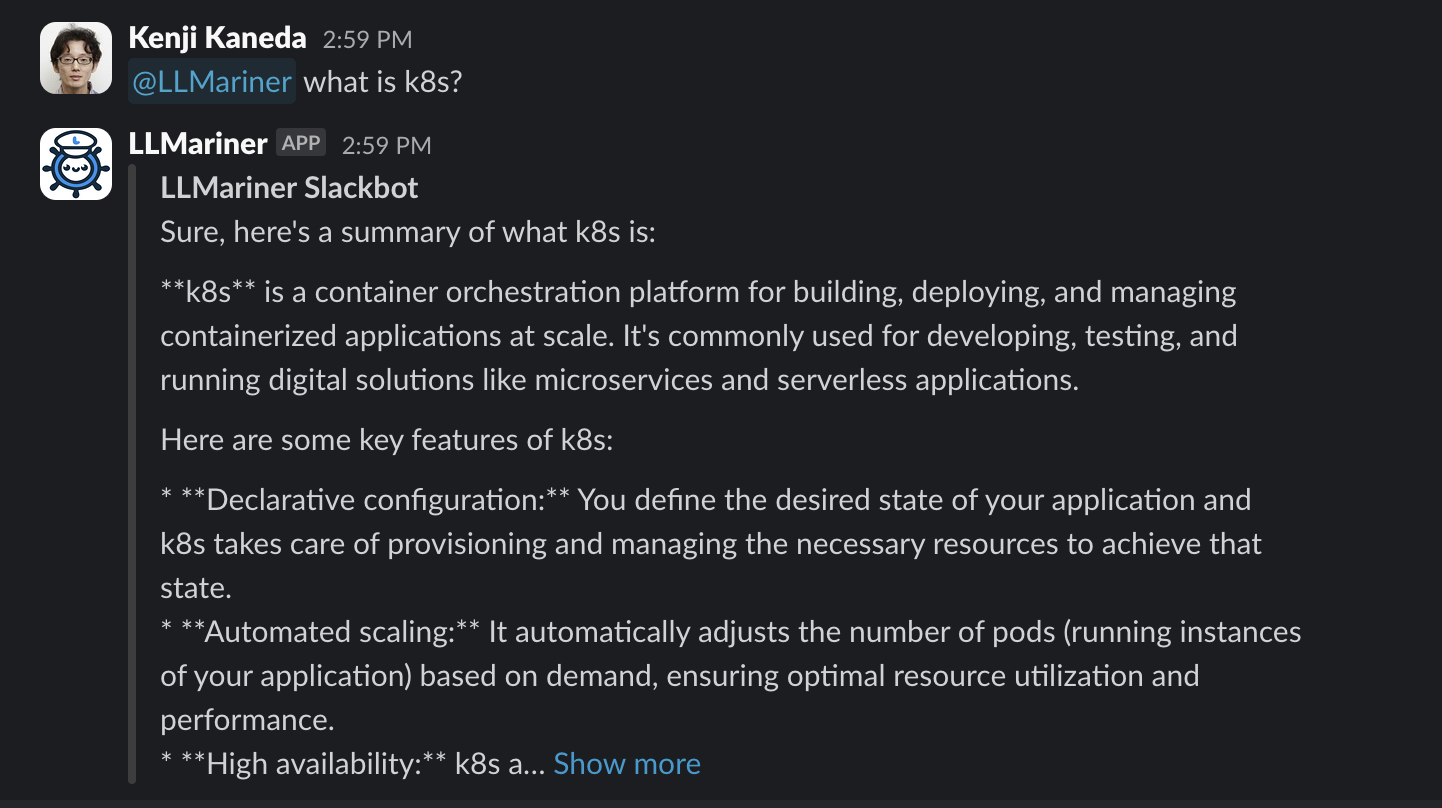
4.9 - MLflow
Integrate with MLflow.
MLflow is an open-source tool for managing the machine learning lifecycle. It has various features for LLMs (link) and integration with OpenAI. We can apply these MLflow features to the LLM endpoints provided by LLMariner.
For example, you can deploy a MLflow Deployments Server for LLMs and use Prompt Engineering UI.
Deploying MLflow Tracking Server
Bitmani provides a Helm chart for MLflow.
helm upgrade \
--install \
--create-namespace \
-n mlflow \
mlflow oci://registry-1.docker.io/bitnamicharts/mlflow \
-f values.yaml
An example values.yaml is following:
tracking:
extraEnvVars:
- name: MLFLOW_DEPLOYMENTS_TARGET
value: http://deployment-server:7000
We set MLFLOW_DEPLOYMENTS_TARGET to the address of a MLflow Deployments Server that we will deploy in the next section.
Once deployed, you can set up port-forwarding and access http://localhost:9000.
kubectl port-forward -n mlflow service/mlflow-tracking 9000:80
The login credentials are obtained by the following commands:
# User
kubectl get secret --namespace mlflow mlflow-tracking -o jsonpath="{ .data.admin-user }" | base64 -d
# Password
kubectl get secret --namespace mlflow mlflow-tracking -o jsonpath="{.data.admin-password }" | base64 -d
Deploying MLflow Deployments Server for LLMs
We have an example K8s YAML for deploying a MLflow deployments server here.
You can save it locally, up openai_api_base in the ConfigMap definition based on your ingress controller address, and then run:
kubectl create secret generic -n mlflow llmariner-api-key \
--from-literal=secret=<Your API key>
kubectl apply -n mlflow -f deployment-server.yaml
You can then access the MLflow Tracking Server, click "New run", and choose "using Prompt Engineering".
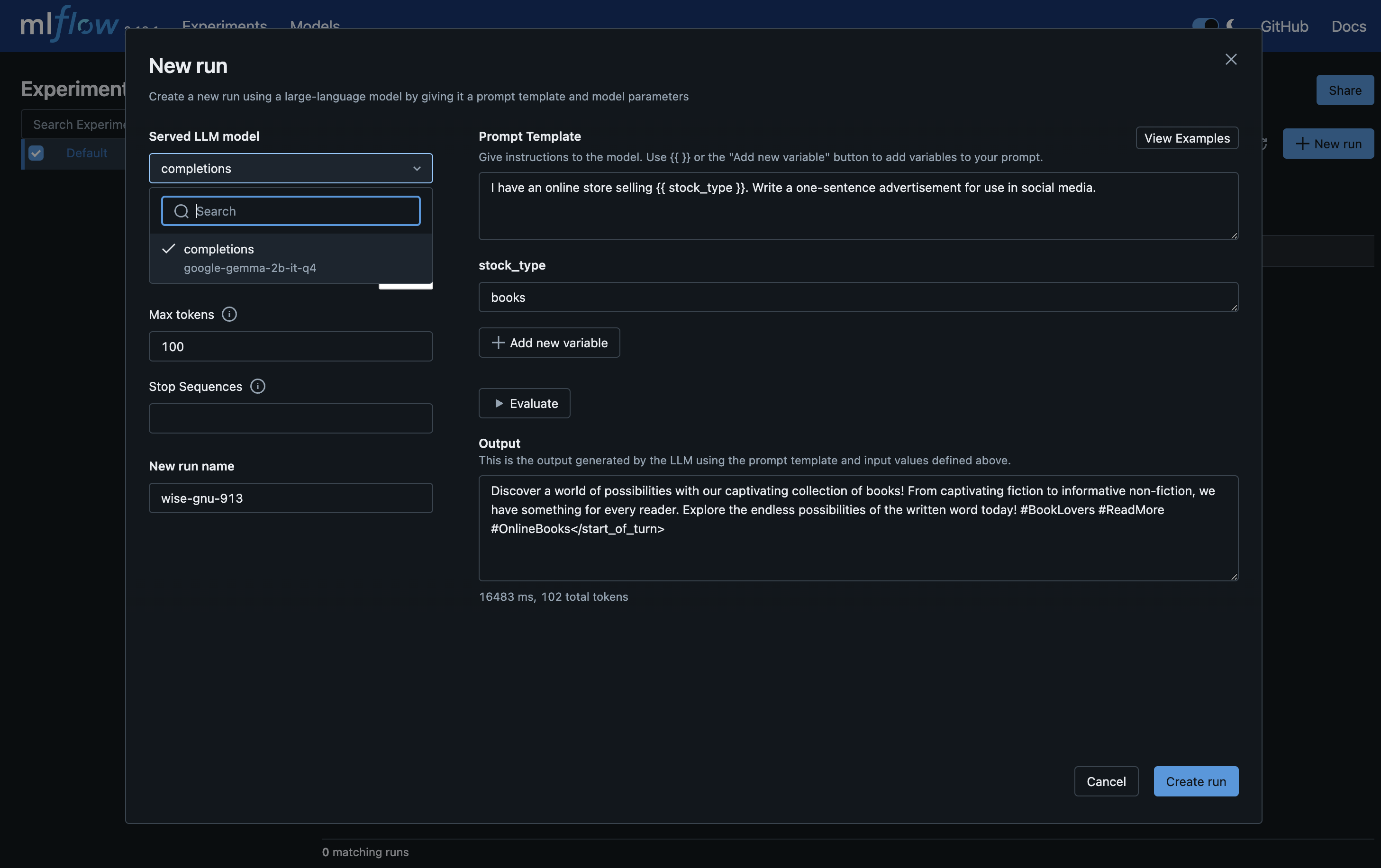
Other Features
Please visit MLflow page for more information for other LLM related features provided by MLflow.
4.10 - Langfuse
Integrate with Langfuse for LLM engineering.
Langfuse is an open source LLM engineering platform. You can integrate Langfuse with LLMariner as Langfuse provides an SDK for the OpenAI API.
Here is an example procedure for running Langfuse locally:
git clone https://github.com/langfuse/langfuse.git
cd langfuse
docker compose up -d
You can sign up and create your account. Then you can generate API keys and put them in environmental variables.
export LANGFUSE_SECRET_KEY=...
export LANGFUSE_PUBLIC_KEY=...
export LANGFUSE_HOST="http://localhost:3000"
You can then use langfuse.openai instead of openai in your Python scripts
to record traces in Langfuse.
from langfuse.openai import openai
client = openai.OpenAI(
base_url="<Base URL (e.g., http://localhost:8080/v1)>",
api_key="<API key secret>"
)
completion = client.chat.completions.create(
model="google-gemma-2b-it-q4_0",
messages=[
{"role": "user", "content": "What is k8s?"}
],
stream=True
)
for response in completion:
print(response.choices[0].delta.content, end="")
print("\n")
Here is an example screenshot.
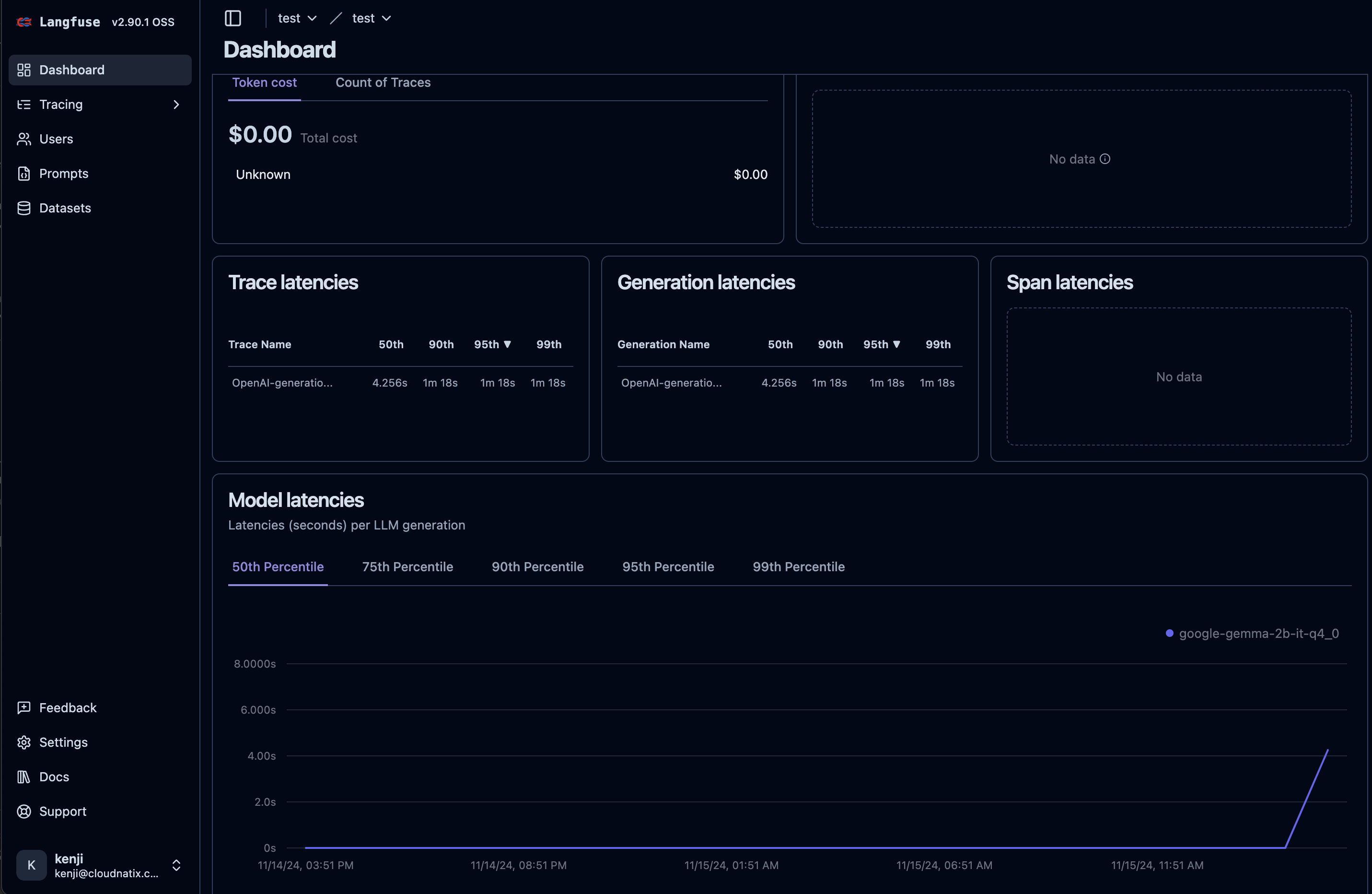
4.11 - Weights & Biases (W&B)
Integration with W&B and see the progress of your fine-tuning jobs.
Weights and Biases (W&B) is an AI developer platform. LLMariner provides the integration with W&B so that metrics for fine-tuning jobs are reported to W&B. With the integration, you can easily see the progress of your fine-tuning jobs, such as training epoch, loss, etc.
Please take the following steps to enable the integration.
First, obtain the API key of W&B and create a Kubernetes secret.
kubectl create secret generic wandb
-n <fine-tuning job namespace> \
--from-literal=apiKey=${WANDB_API_KEY}
The secret needs to be created in a namespace where fine-tuning jobs run. Individual projects specify namespaces for fine-tuning jobs, and the default project runs fine-tuning jobs in the "default" namespace.
Then you can enable the integration by adding the following to your Helm values.yaml and re-deploying LLMariner.
job-manager-dispatcher:
job:
wandbApiKeySecret:
name: wandb
key: apiKey
A fine-tuning job will report to W&B when the integration parameter is specified.
job = client.fine_tuning.jobs.create(
model="google-gemma-2b-it",
suffix="fine-tuning",
training_file=tfile.id,
validation_file=vfile.id,
integrations=[
{
"type": "wandb",
"wandb": {
"project": "my-test-project",
},
},
],
)
Here is an example screenshot. You can see metrics like train/loss in the W&B dashboard.
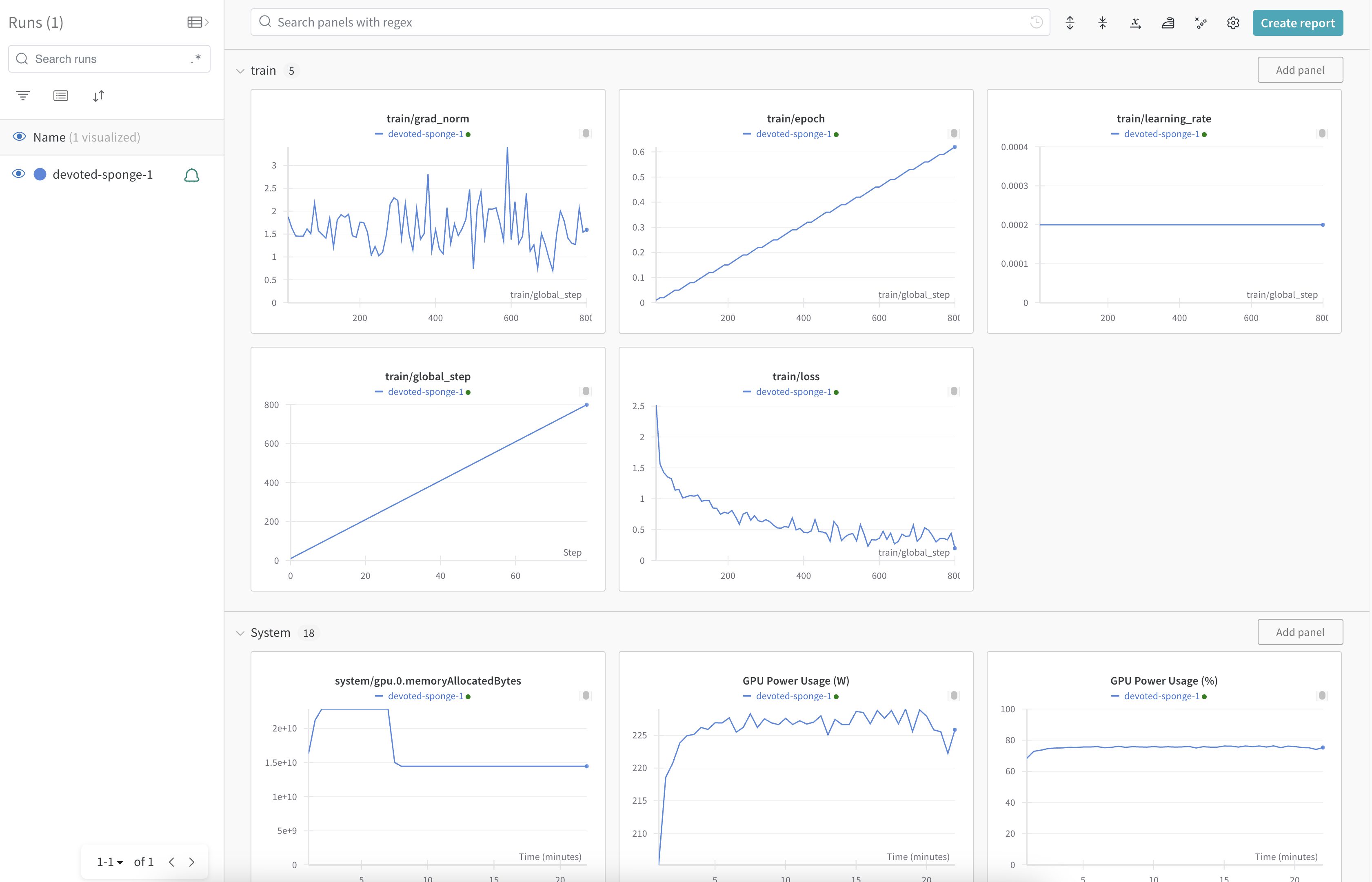
Note
The W&B API key is attached to fine-tuning jobs as an environment variable. Please be careful of its visibility.5 - Development
Documents related to development
5.1 - Technical Details
Understand LLMariner technical details.
Components
LLMariner provisions the LLM stack consisting of the following micro services:
- Inference Manager
- Job Manager
- Model Manager
- File Manager
- Vector Store Server
- User Manager
- Cluster Manager
- Session Manager
- RBAC Manager
- API Usage
Each manager is responsible for the specific feature of LLM services as their names indicate. The following diagram shows the high-level architecture:
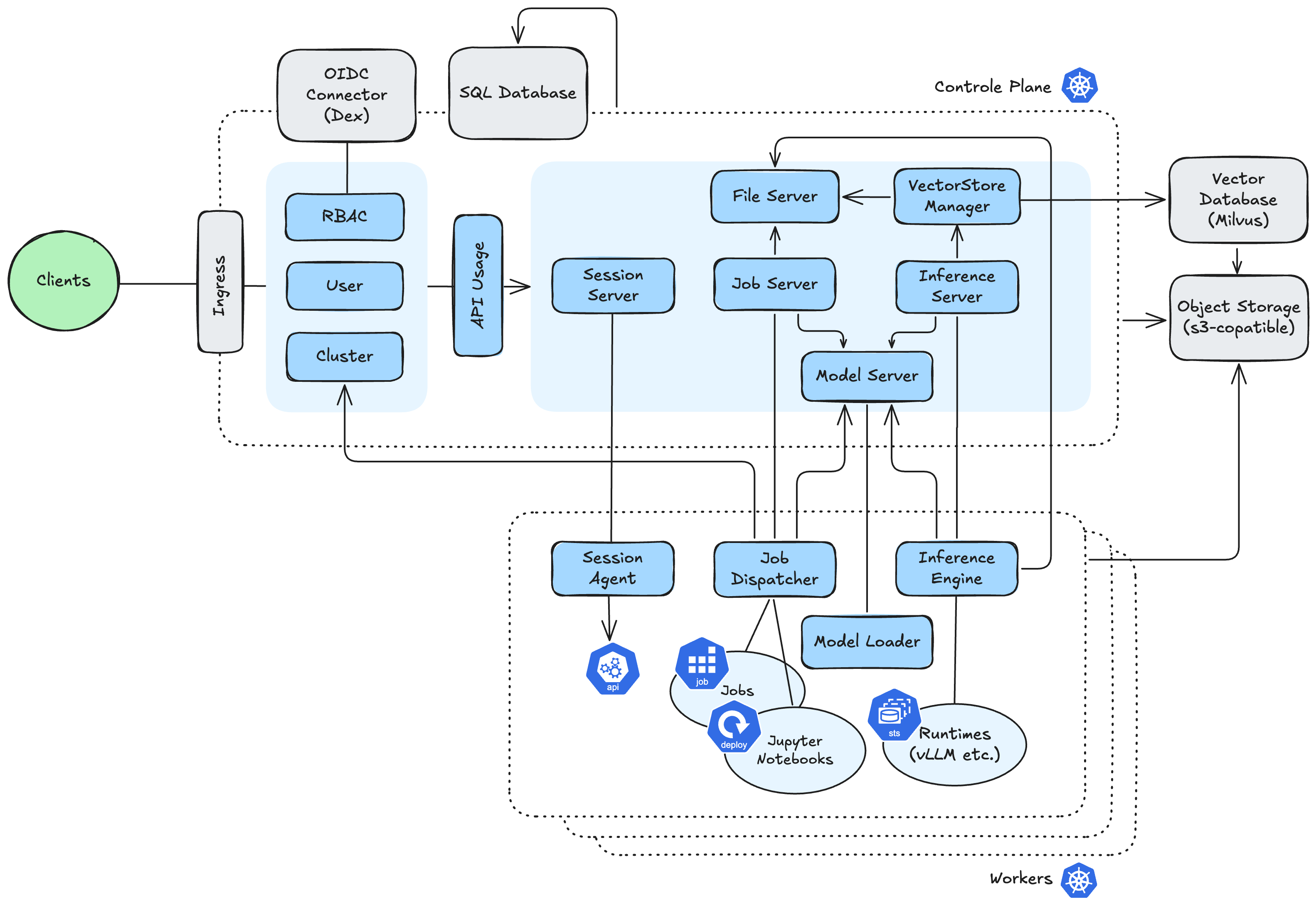
LLMariner has dependency to the following components:
Ingress controller is required to route traffic to each service. SQL database and S3-compatible object store are used to persist metadata (e.g., fine-tuning jobs), fine-tuned models, and training/validation files. Dex is used to provide authentication.
Key Technologies
Autoscaling and Dynamic Model Loading in Inference
Inference Manager dynamically loads models up on requests it receives. It also dynamically auto-scales pods based on demand.
Session Manager: Secure Access to Kubernetes API Server
LLMariner internally accesses Kubernetes API server to allow end users to access logs of fine-tuning jobs, exec into a Jupyter Notebook, etc. As end users might not have direct access to a Kubernetes API server, LLMariner uses Session Manager to provide a secure tunnel between end users and Kubernetes API server.
Session Manager consists of two components: server and agent. The agent establishes HTTP(S) connections to the server and keeps the connections. Upon receiving a request from end users, the server forwards the request to the agent using one of the established connections. Then the agent forwards the request to the Kubernetes API server.
This architecture enables the deployment where the server and the agent can run in separate Kubernetes clusters. As the agent initiates a connection (not the server), there is no need to open incoming traffic at the cluster where the agent runs. An ingress controller is still the only place where incoming traffic is sent.
Quota Management for Fine-tuning Jobs
LLMariner allows users to manage GPU quotas with integration with Kueue.
5.2 - Roadmap
Future plans
Milestone 0 (Completed)
- OpenAI compatible API
- Models:
google-gemma-2b-it
Milestone 1 (Completed)
- API authorization with Dex
- API key management
- Quota management for fine-tuning jobs
- Inference autoscaling with GPU utilization
- Models:
Mistral-7B-Instruct,Meta-Llama-3-8B-Instruct, andgoogle-gemma-7b-it
Milestone 2 (Completed)
- Jupyter Notebook workspace creation
- Dynamic model loading & offloading in inference (initial version)
- Organization & project management
- MLflow integration
- Weights & Biases integration for fine-tuning jobs
- VectorDB installation and RAG
- Multi k8s cluster deployment (initial version)
Milestone 3 (Completed)
- Object store other than MinIO
- Multi-GPU general-purpose training jobs
- Inference optimization (e.g., vLLM)
- Models:
Meta-Llama-3-8B-Instruct,Meta-Llama-3-70B-Instruct,deepseek-coder-6.7b-base
Milestone 4 (Completed)
- Embedding API
- API usage visibility
- Fine-tuning support with vLLM
- API key encryption
- Nvidia Triton Inference Server (experimental)
- Release flow
Milestone 5 (In-progress)
- Frontend
- GPU showback
- Non-Nvidia GPU support
- Multi k8s cluster deployment (file and vector store management)
- High availability
- Monitoring & alerting
- More models
Milestone 6
- Multi-GPU LLM fine-tuning jobs
- Events and metrics for fine-tuning jobs